Сделав полное и правильное семантическое ядро (СЯ) для информационного сайта, вы исправно будете получать трафик из поиска по охваченным запросам. А также сможете проверять, по каким запросам сайт ранжируется в топе, а какие в него не вошли.
Правильное семантическое ядро для информационного сайта – это постоянный поток трафика из поисковых систем. Чем полнее оно охватывает тематику, тем больше посещений получает ваш сайт.

СЯ необходимо и для аналитики – вы сможете отслеживать, по каким запросам сайт уже в топе, а по каким страницы нужно доработать, чтобы собрать еще больше трафика.
Зачем нужно семантическое ядро для информационного сайта
Семантическое ядро – это список запросов, по которым информационный сайт будет представлен в выдаче. По ним он получит посетителей из Яндекса и Гугла.
Для составления семантического ядра нужно собрать все поисковые запросы, связанные с темой сайта, разделить их на смысловые группы (кластеры) и под каждую группу сделать статью.
Таким образом, каждая статья будет отвечать на конкретные запросы пользователей и получать по ним трафик.
Какие запросы нужно брать для информационного сайта
Ключевые слова для информационного сайта часто начинаются с вопросительного слова. Например, «как сделать забор из профнастила», «как получить выплату на ребенка», «где находится сердце».
Впрочем, это необязательно. Например, запросы «мировой рекорд по планке», «рецепт картошки в духовке», «самый населенный город мира» вопросительного слова не содержат, однако относятся к информационным.
Чтобы определить, нужно ли брать запрос в ядро сайта, посмотрите, какие сайты ранжируются по нему.
Возьмем запрос «забор из профнастила». По нему выдача 100% коммерческая, это значит, что люди, вводя этот запрос, хотят купить или заказать забор из профнастила, а вовсе не сделать его самостоятельно или узнать какую-либо информацию о нем.
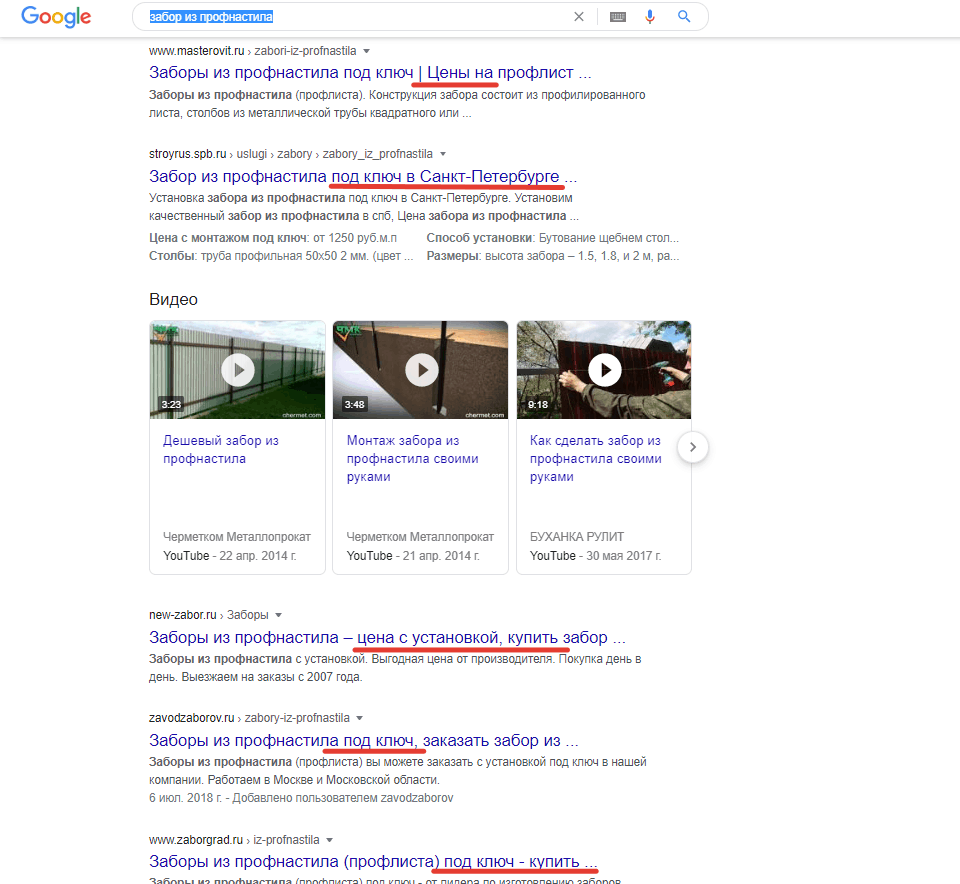
По таким запросам нет смысла продвигать информационную страницу, она все равно не попадет в топ выдачи.
А вот запрос «забор из профнастила своими руками» – то что нужно для информационной статьи.
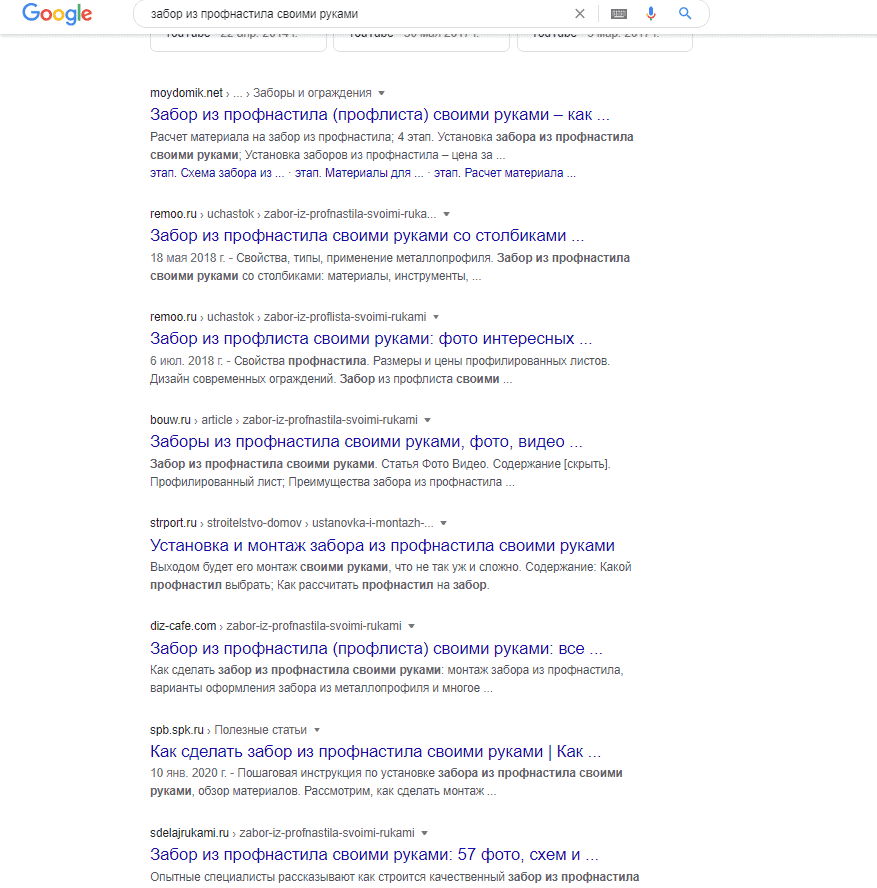
Бывает выдача смешанная, когда ранжируются и продающие сайты, и информационные. В таких случаях нужно брать ключ в ядро.
Однако конкуренция по нему будет сильнее, так как придется побороться за топ выдачи не только с информационными сайтами, но и с коммерческими.
Если непонятно, стоит ли брать ключ в семантическое ядро сайта – посмотрите, какие типы сайтов ранжируются по нему в выдаче.
Как собрать маркеры
Для сбора маркеров нужно:
- Составить список конкурентов и взять с них ключи для дальнейшего парсинга.
- Посмотреть в Вордстате, что было упущено.
Сбор маркеров с сайтов конкурентов
Допустим, мы хотим собрать ядро про полы («как сделать пол своими руками» и т. п.).
Для сбора ключей с сайта-конкурента введем целевой ключ в поиск и зайдем на один из информационных сайтов.
Например, по запросу «как уложить ламинат», первый сайт в Гугле – сайт Леруа Мерлен. Но его мы брать не будем, так как его тематика шире, сайт посвящен стройматериалам, строительству и ремонту.
А следующий сайт нам подходит, он только о полах.
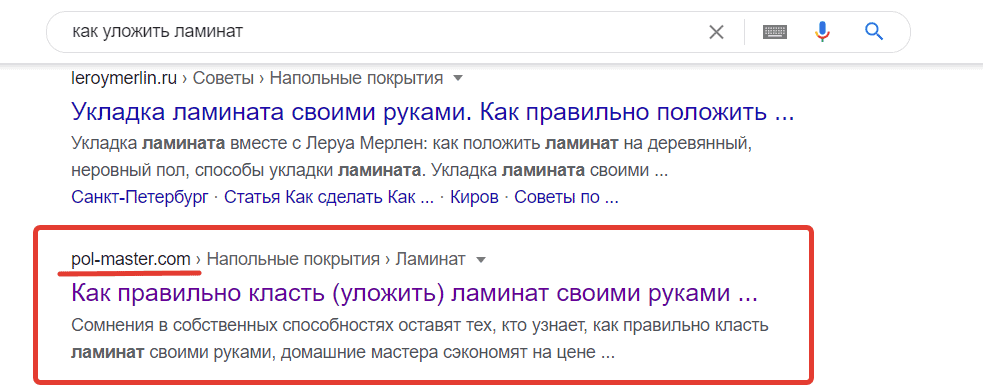
Заходим на этот сайт и находим на нем карту сайта, обычно она размещена в подвале.
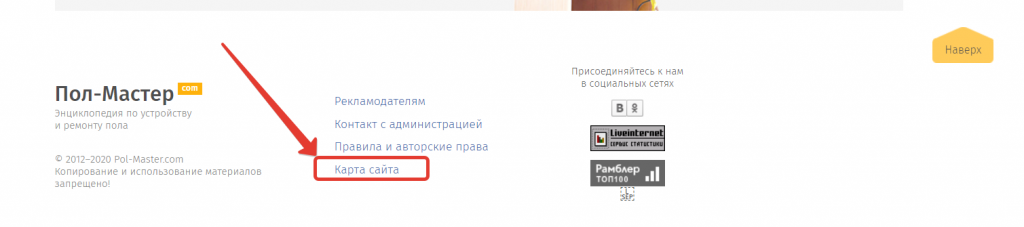
В карте необходимо взять самые широкие фразы, характеризующие нашу тематику.

Для группообразующих слов морфологическая форма не важна, главное, охватить все ключи, по которым будут собираться хвосты на следующем этапе.
Таким образом проходим по всей карте сайта у нескольких топовых конкурентов.
В итоге получаем для парсинга от 100 до 1 000 маркеров в среднем, в зависимости от выбранной тематики.
Сбор маркеров с помощью Вордстат
В Вордстате также можно найти слова, которые были упущены при сборе с конкурентов.
При вводе широкого ключа из нашей тематики, например, «ламинат», в правой колонке Вордстат предложит похожие ключи.
Если там окажутся упущенные запросы, добавим их в список маркеров.
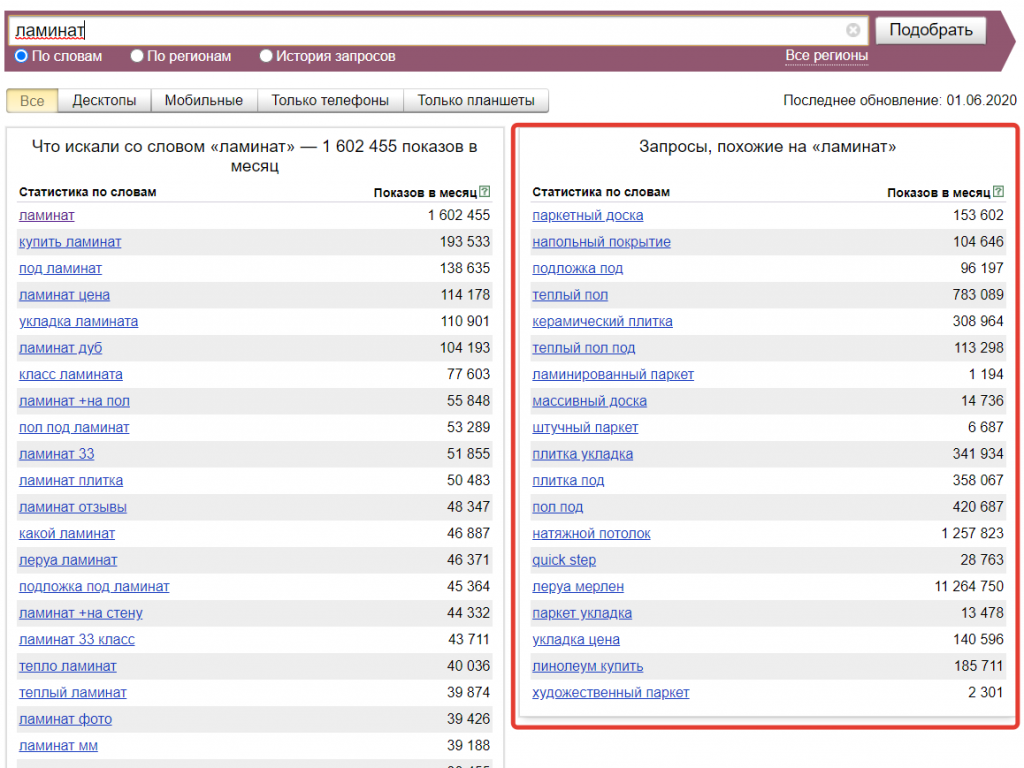
То, что в левой колонке, будет собрано при помощи парсинга на следующем этапе.
Как расширить ядро
Помимо Вордстата, можно собрать ключи для информационного сайта и из других источников:
- Базы ключевых слов. Есть как бесплатные с ограничениями, например, Букварикс, так и платные – Keys.sо, База Пастухова, SpyWords. Некоторые из них позволяют выгрузить видимость конкурентов. Подробнее о выгрузке ключевых слов конкурентов →
- Поисковые подсказки. По тем же маркерам можно спарсить и подсказки Яндекса и Гугла. Это делается в программе KeyCollector (КейКоллектор).
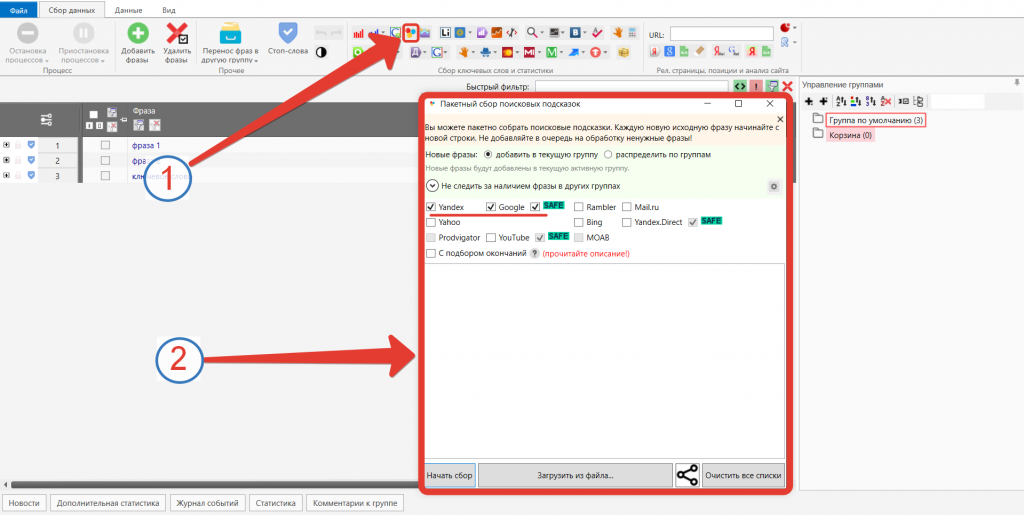
Учтите, что при использовании дополнительных источников количество мусорных запросов возрастет. Особенно этим грешат поисковые подсказки.
Инструменты для парсинга
Чтобы получить хвосты ранее собранных маркеров, можно воспользоваться следующими инструментами.
Программы:
- Программа СловоЕб – подходит для работы с небольшими ядрами. Частотности собирает долго, но зато бесплатно. О том, как парсить программой Словоеб, читайте в нашей статье →
- Программа КейКоллектор – платный софт, умеет парсить не только Вордстат, но и подсказки Яндекса, Гугла и Гугл Адвордса, и обладает еще множеством возможностей. Стоит 1 800 рублей единоразово. Скачать и оплатить лицензию можно на официальном сайте.
Онлайн-сервисы:
- Rush Analytics.
- Mutagen.
Подробнее о парсерах ключевых слов →
Парсинг с помощью КейКоллектора
После установки программы и создания проекта добавляем собранные маркеры для парсинга Вордстат.
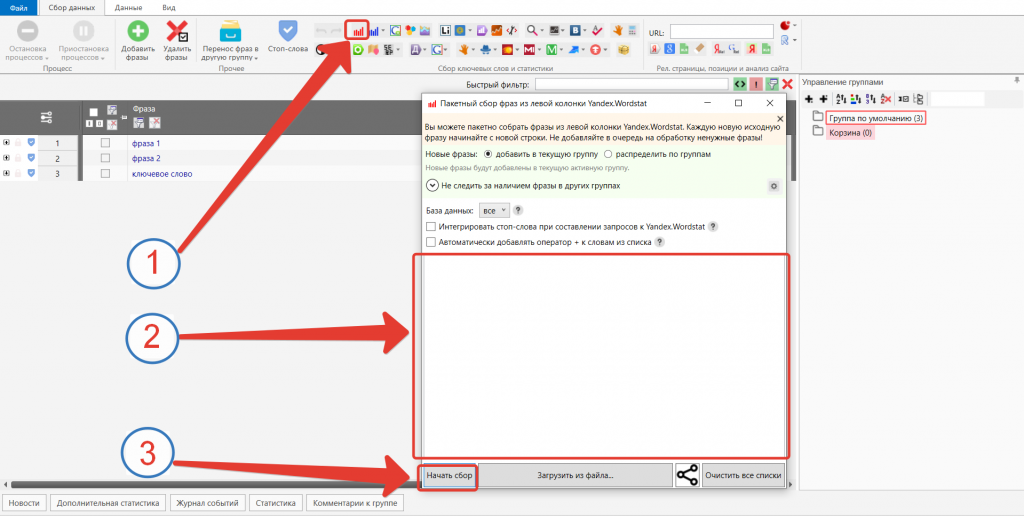
Когда все хвосты будут собраны, начнем собирать частотности. Лучше всего это делать с помощью инструмента Директ.
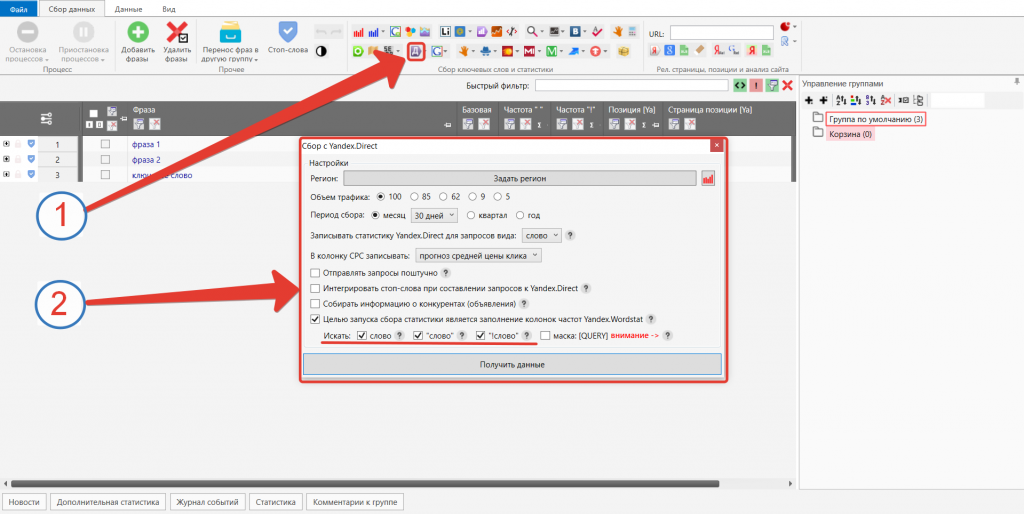
Теперь все ключи и их частотности собраны. Можно приступить к чистке ядра.
Если есть выгрузка ключевых слов из баз, то просто добавим их в программу кнопкой «Добавить фразы». И снимем у них частотности.
На следующем этапе стоит избавиться от мусора – от тех фраз, которые точно не понадобятся для продвижения. Например: форум, википедия, ютуб и т. д.
Для этого используем инструмент «Стоп-слова».
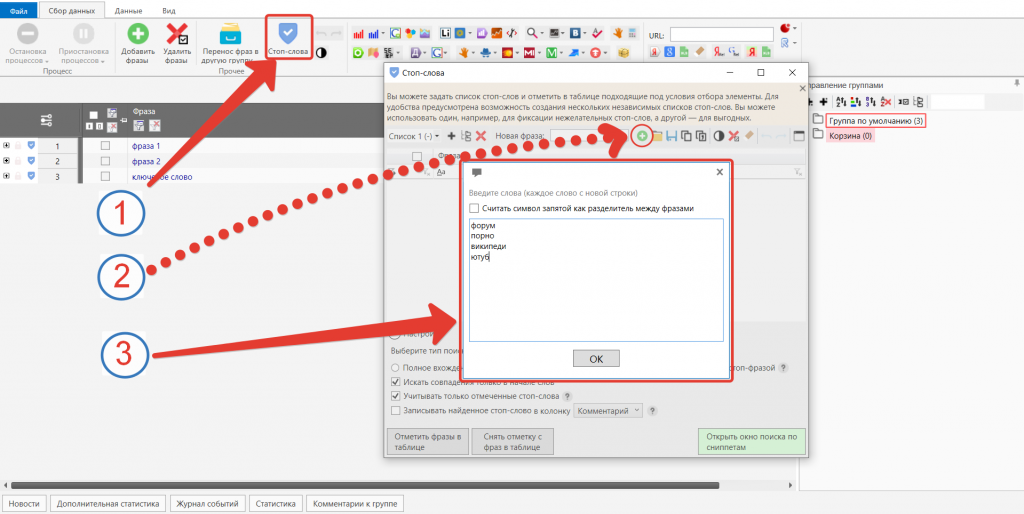
Также стоит избавиться от фраз с нулевой ”!частотой”. А если ядро большое (от 5 000 ключей), то лучше подрезать точную частотность и удалить все ключи, имеющие частотность “!” меньше 10, а в некоторых случаях (особенно, если ниша сезонная) и меньше “!5”.
Как правильно группировать запросы
Чтобы сделать правильные группы, объединяйте фразы в соответствии с двумя правилами:
- По смыслу. Ключевые слова отвечают на один и тот же вопрос пользователя. Например, «как постелить линолеум своими руками» и «укладка линолеума самостоятельно». Такие запросы нужно объединить в одну группу.
- По выдаче. Выдача по запросам пересекается. Чтобы убедиться, что запросы кластеризуются вместе, проверяйте выдачу.
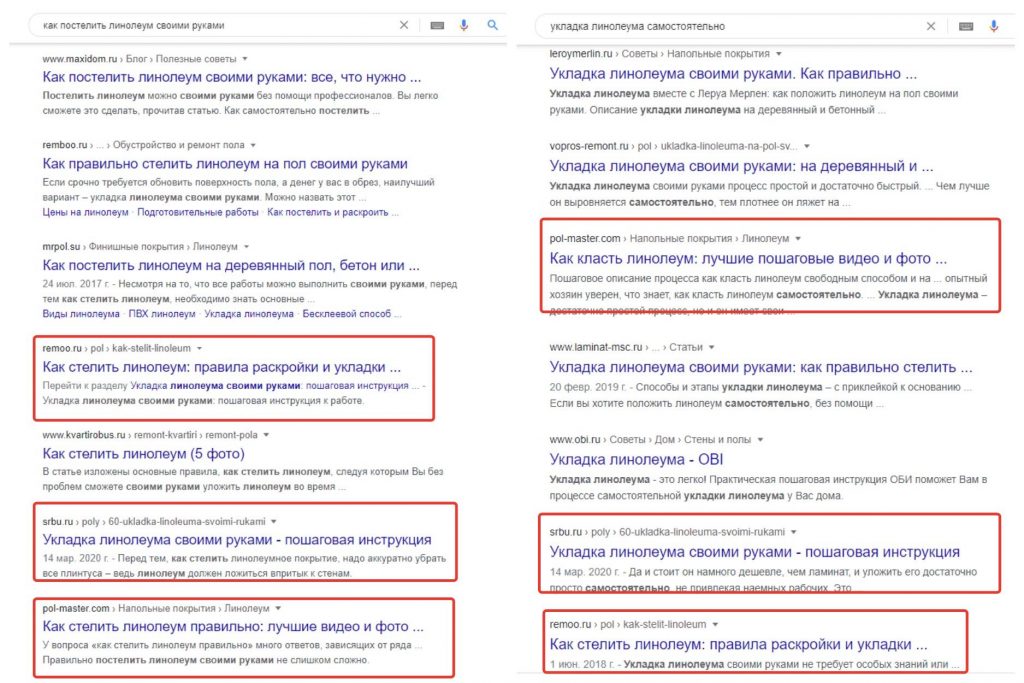
Из скриншота видно, по запросам «как постелить линолеум своими руками» и «укладка линолеума самостоятельно» три УРЛ пересекаются. Значит, нужно объединять их в один кластер.
Если и после проверки выдачи остались сомнения, можно проверить в другой поисковой системе. Если и там непонятно что делать, то открываем сайты и смотрим, о чем идет речь. После этого должно быть понятно – объединять или разделять запросы.
Инструменты для группировки
Кластеризовать запросы информационного сайта можно с помощью нескольких инструментов:
- КейКоллектор – группирует на основе поисковой выдачи, по содержанию фраз и полностью вручную.
- Key Assort – группирует автоматически на основе выдачи. Платный софт, устанавливается на компьютер, стоит 1 990 рублей единоразово.
Об этих и других сервисах для кластеризации читайте в нашей статье →
Группировка СЯ вручную на сервисе Workflow.team
Для онлайн группировки семантического ядра информационного сайта лучше использовать Workflow.team.
Почему стоит выбрать сервис
Преимущества сервиса перед аналогами:
- Есть облачный доступ с любого устройства к личному кабинет.
- Возможность группировать несколько сайтов, создав для каждого отдельный проект.
- Удобная работа с ручной семантикой.
- Можно снимать позиции ключей, добавив свои XML лимиты.
- Можно видеть, сколько посетителей было у каждой группы, привязав ключ Метрики.
- Сервис пока бесплатный.
Как группировать в Workflow
Для группировки создадим проект и загрузим ключи.
Файл в формате CSV для загрузки должен иметь 4 столбца (ключ,частотность общая,”частотность”,”!частотность”), первая строка – это шапка. Такой файл выгружается из КейКоллектора.
Первая колонка – это структура сайта. Здесь можно задавать разделы и в дальнейшем перемещать группы между ними, а также менять вложенность разделов.
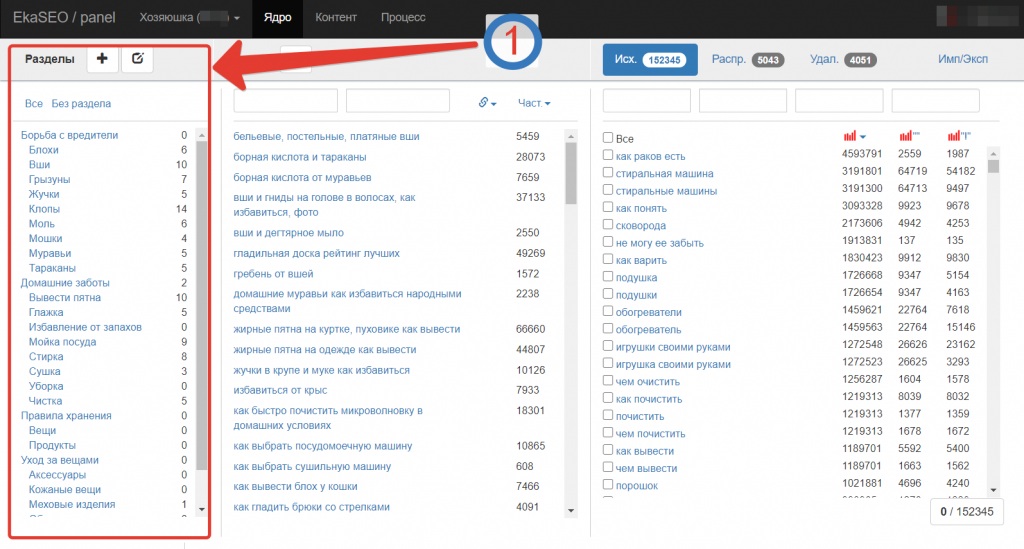
Вторая колонка – место, где будут отображаться все созданные группы. Здесь есть два фильтра, чтобы было удобно искать группы, когда их будет много. Фильтры ищут по кусочкам слова и по УРЛ, если ссылка привязана к группе.
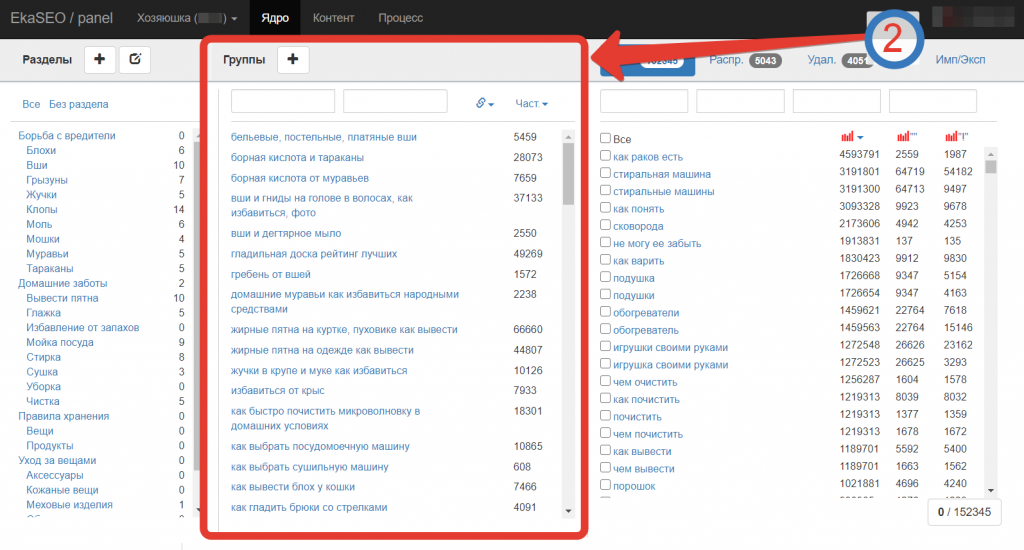
Третья колонка – ключи ядра сайта. Здесь собраны все ключи и отсюда же нужно их группировать.
Для группировки отметим галочкой те ключи, которые нужно объединить в одну группу. Под колонкой нажмем «Создать группу», если запросы нужно объединить, или на логотип корзины, если их необходимо удалить.
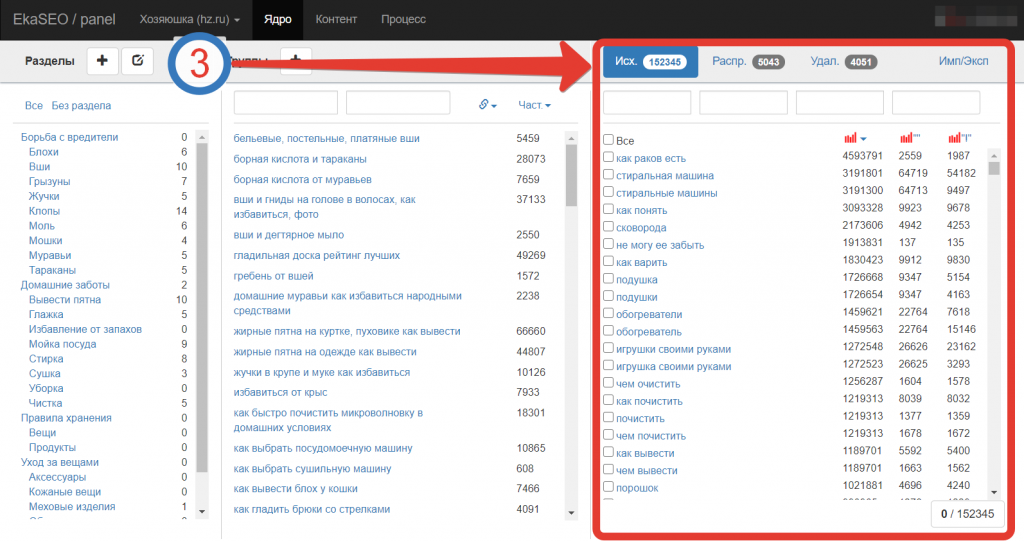
В результате группировки у нас будет структура сайта и группы, под которые можно заказывать статьи.
Если вы не хотите заниматься созданием и группировкой семантического ядра, то это можно делегировать профессионалам. Заказать семантику для сайта →
Заключение
Когда будет готово семантическое ядро для информационного сайта, можно снимать позиции и проверять, какие группы и статьи требуют доработки, а какие вышли в топ и приносят трафик.
А если есть куда расширяться, то смело загружайте новое ядро для новой рубрики и продолжайте развивать свой информационный проект.
Отправляя сообщение, Вы разрешаете сбор и обработку персональных данных. Политика конфиденциальности.