Кей Коллектор (Key Collector) – десктопная программа для работы с семантическим ядром сайта. В ней много функций для сбора данных по ключевым словам из разных сервисов.

Также Кей Коллектор помогает группировать ключевые фразы автоматически и вручную.
Как установить программу на компьютер
Оплатите и скачайте программу на официальном сайте. Цена одной лицензии 1 800 рублей.

Запустите установочный файл скачанной программы и следуйте инструкции.
После установки нужно активировать лицензию:
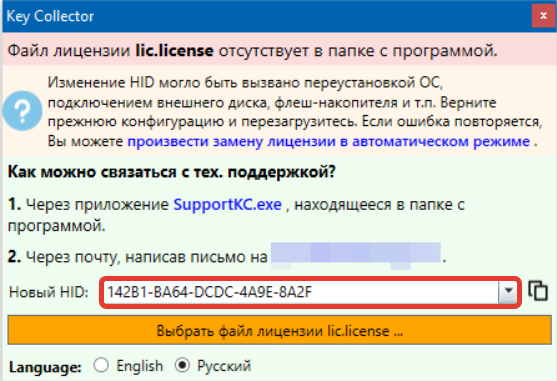
- При запуске установленной программы появится окно с уникальным идентификатором (HID).
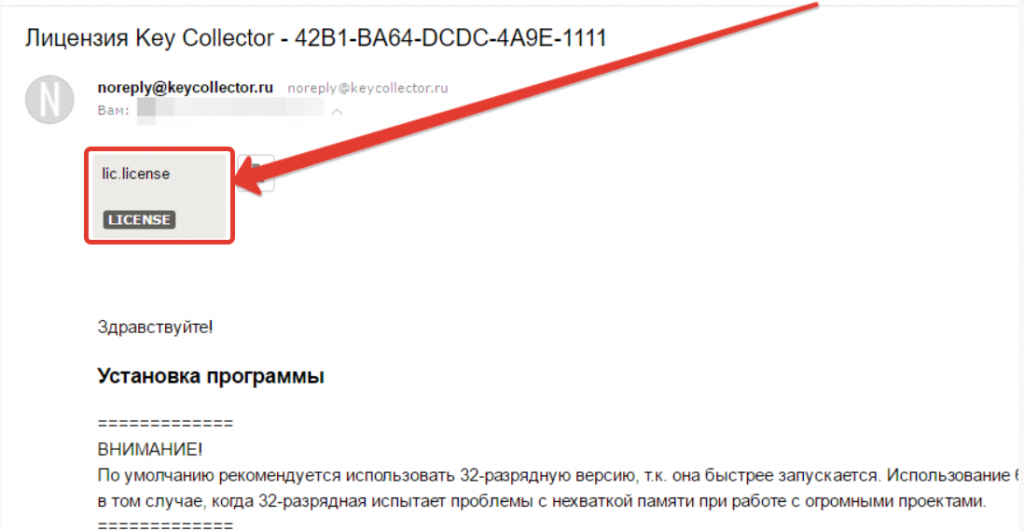
- Лицензия (файл lic.license) придет на почтовый ящик после оплаты, ее нужно положить в папку с программой. По умолчанию Кей Коллектор устанавливается в «Мои документы/Key Collector».
- Можно запускать программу и пользоваться.
Если возникли трудности, ищите всю информацию по инсталляции на сайте программы.
Настройка программы
Первым делом нужно настроить парсинг под ваши задачи. Для этого нажмите на шестеренку в верхнем левом углу.
Первоначальные настройки
В открывшемся окне, в разделе «Общие», есть несколько блоков. Разберемся, какие настройки нужно выставить.
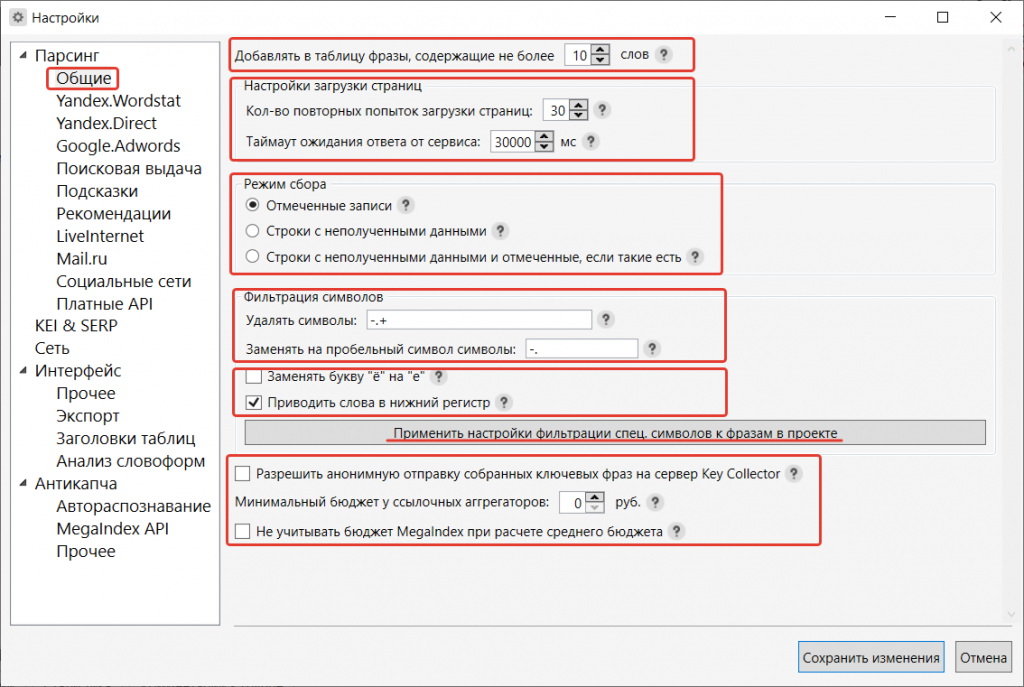
- В первой строке «Добавлять в таблицу фразы, содержащие не более N слов» лучше ставить 12 или более слов – если вы используете выгрузки ключевых слов из баз, там запросто могут быть ключи из 10 и более слов. Количество слов во фразе зависит и от тематики сайта.
- Настройки загрузки страниц можно оставить по умолчанию, как есть.
- Режим сбора. Если это первый сбор, нужно выбрать второй пункт, а если вам необходимо переснять текущие данные – первый пункт: «Отмеченные записи». При этом ключи должны быть отмечены в таблице.
- Фильтрация символов. Сюда можно добавить те символы, которые автоматически удалятся при добавлении слов в таблицу.
- «Заменять букву ё на е» и «Приводить слова в нижний регистр» рекомендуется отметить, чтобы ключи добавлялись в корректном виде.
- Кнопка «Применить настройки фильтрации спец. символов к фразам в проекте» позволит ранее рассмотренные настройки применить к уже имеющемуся запущенному проекту.
- Последний блок – на ваше усмотрение. А бюджет и Мегаиндекс на первоначальном этапе настроек не нужны.
Настройка Вордстат Яндекс
В следующем разделе нужно настроить парсинг Яндекс Вордстата. Для этого перейдите в одноименный раздел в меню слева.
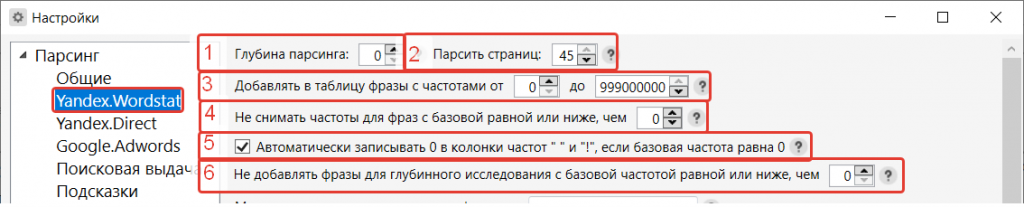
- В «Глубине парсинга» оставьте 0, если не требуется парсить по второму кругу то, что было получено при первом подходе парсинга.
- Количество страниц оставьте максимальное, чтобы собрать все хвосты ключевого слова.
- Добавление частотностей лучше оставить от 0 до максимальной. Если выставить другие значения, частотность будет добавлена не для всех фраз.
- В следующем пункте можно оставить 0, если планируете удалять фразы с нулевой частотностью. Или 10, если удаляете фразы с частотностью меньше 10.
- Автоматическое проставление нуля поможет сэкономить на антикапче. Если не планируете работать с фразами, имеющими нулевую частотность, или например, с фразами, у которых частотность ниже 10, то ставьте галочку в чекбокс.
- Если в пункте «Глубина парсинга» задано значение больше нуля, то настройка «Не добавлять фразы для глубинного исследования с базовой частотой равной или ниже, чем», например, 5, поможет сэкономить время и антикапчу, исключив фразы с частотностью ниже отмеченного уровня.
В пункте «Пользовательская маска запроса» стоит задать: «[!QUERY]». Этот вариант для снятия частотности фразы с учетом морфологии и порядка слов.
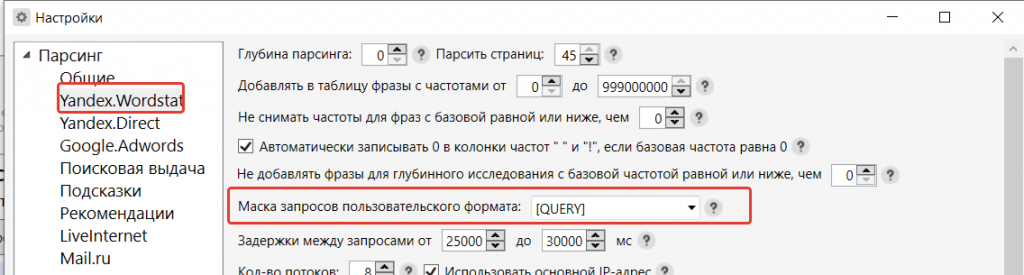
Маска запросов нужна для снятия Wordstat, найти ее можно в меню инструментов, как показано на скриншоте ниже.
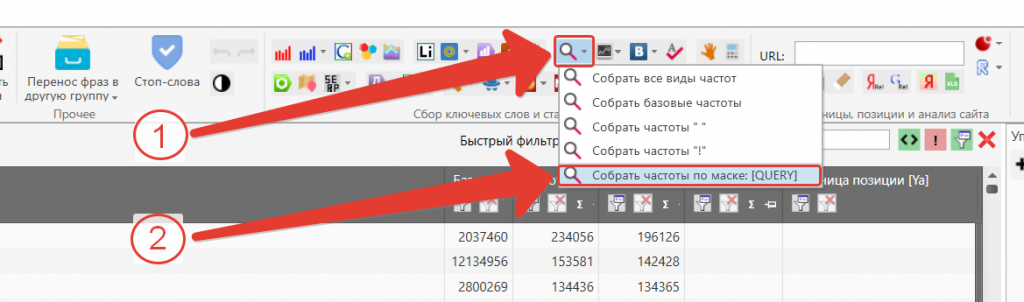
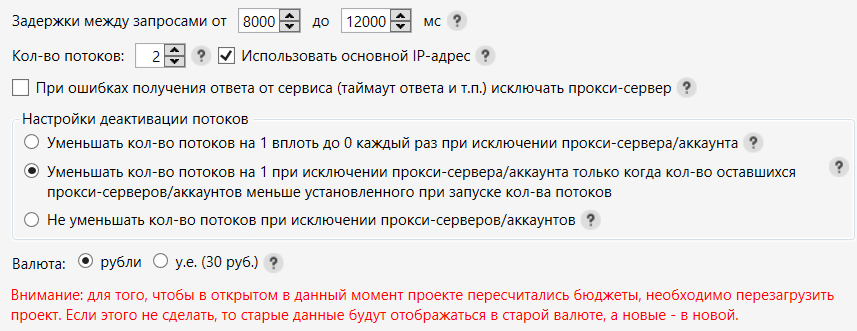
Задержку между запросами рекомендуется оставить по умолчанию.
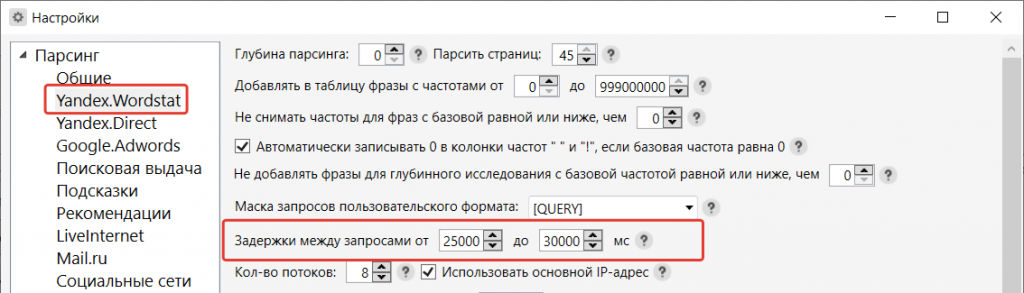
Следующий пункт – количество потоков. Оставьте 1 поток + галочка «Использовать основной IP-адрес», если не используете прокси.
Таймаут ожидания от сервиса и задержку после авторизации оставляйте по умолчанию.
Следующий пункт нужен, если используются прокси. Для Шаред прокси или бесплатных можно включить настройку, чтобы отсечь плохие сервера и оставить только рабочие.
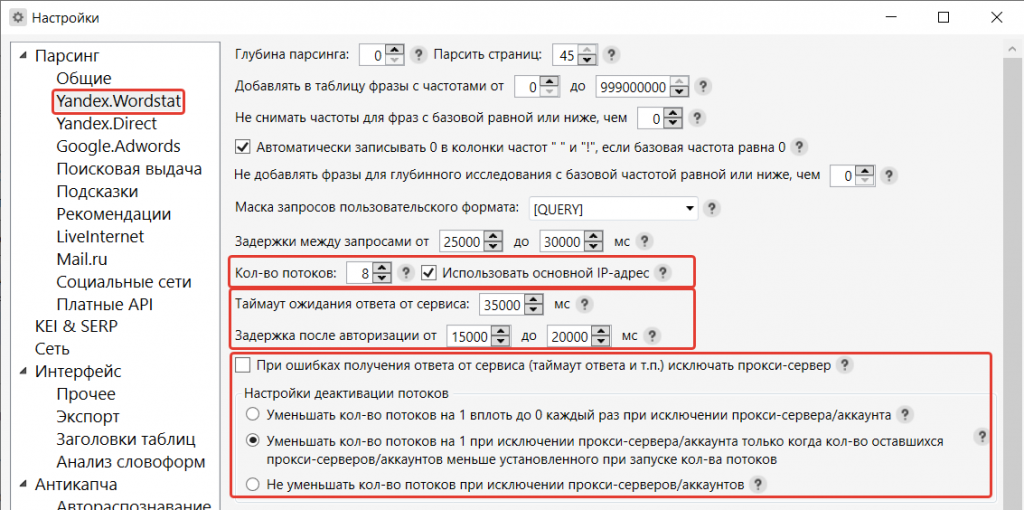
Вычисление медианы и среднего арифметического можно оставить по умолчанию. В большинстве случаев этим функционалом не придется пользоваться, он нужен для вычисления частотности у сезонных запросов.
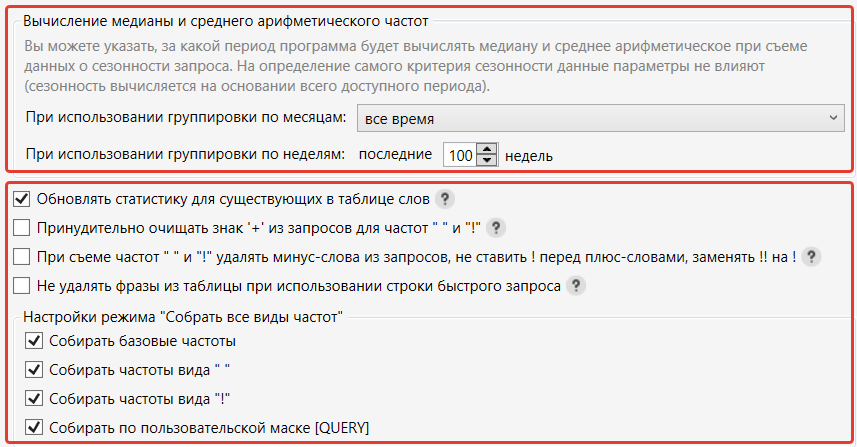
Следующая настройка помогает перезаписать данные при съеме из других сервисов.
Последний пункт говорит о том, какие данные необходимо снять при выборе «Собрать все виды частот».
Аккаунт Яндекс
Чтобы добавить аккаунт Яндекса в программу, перейдите в пункт меню «Yandex Direct».
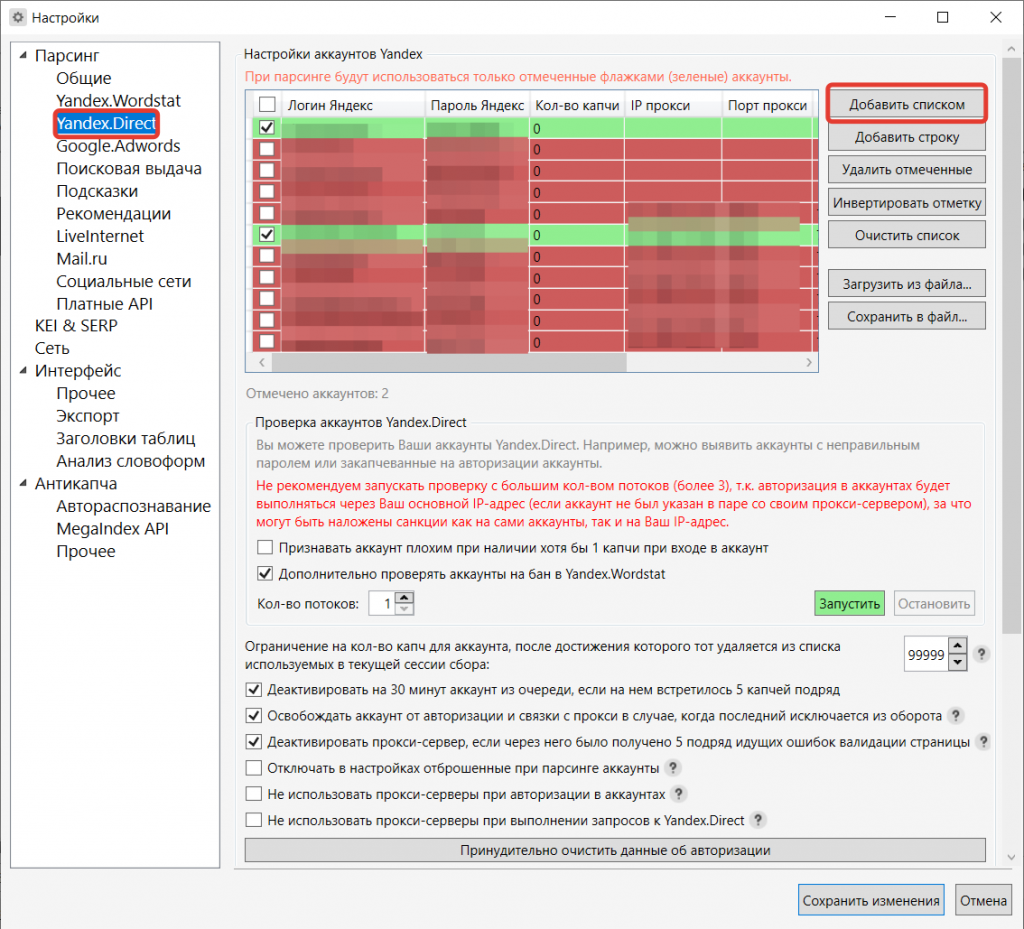
Нажмите кнопку «Добавить списком» или «Добавить строку».
Помните, Кей Коллектор принимает только те аккаунты, которые расположены на домене @yandex.ru
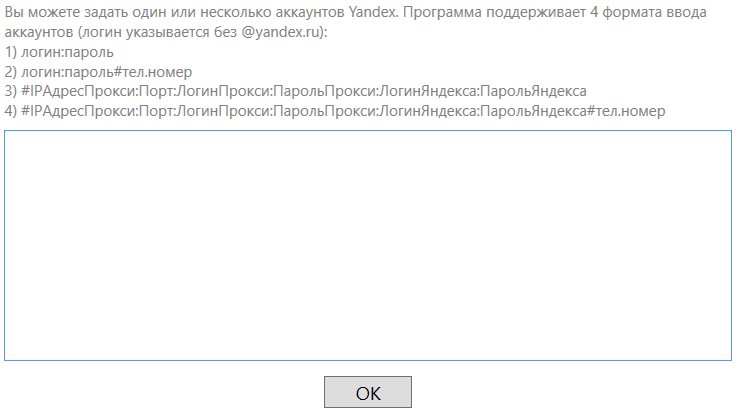
На скриншоте выше видно, что добавить аккаунты в программу можно различными способами, в том числе с телефоном и сразу же с прокси, если такие используются.
После добавления можно протестировать аккаунты.
Есть возможность задать ограничение по количеству капч на аккаунт, чтобы отбрасывать те, которые потребляют много антикапчи. А далее выбрать, что делать с такими аккаунтами.
Затем можно выставить задержку между запросами как есть или увеличить ее, если аккаунт съедает много капчи.
Количество потоков выставляется равное количеству прокси и + 1, если используется основной IP-адрес.
Аккаунт Гугл
Настройки аккаунта Гугл позволят снимать данные в Adwords. Выберите соответствующий пункт меню слева.
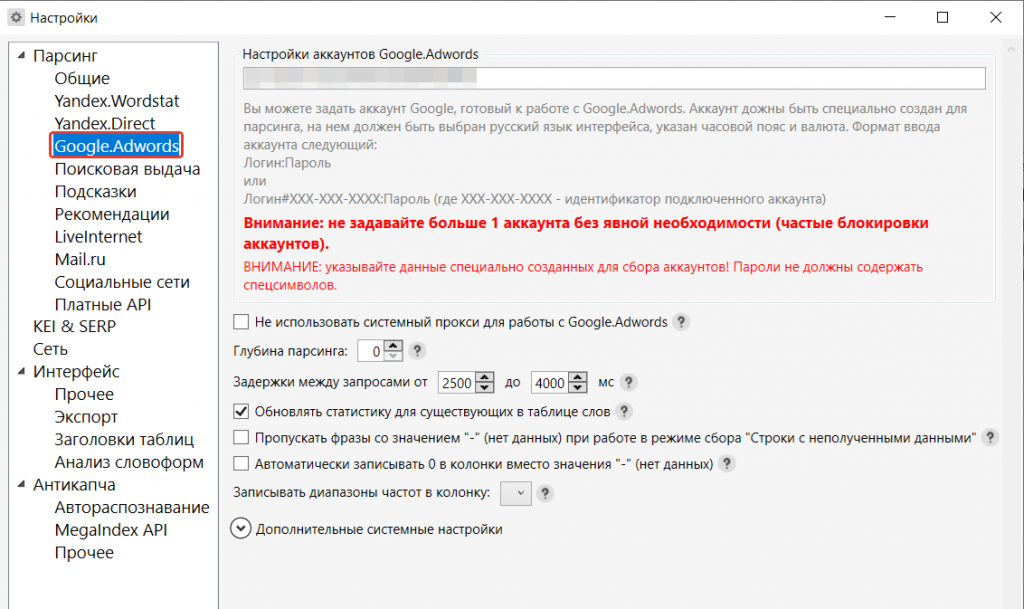
Добавлять аккаунт нужно в следующем виде: gmail:password. Саму почту @gmail.com вводить не надо, только все до значка @.
Остальные настройки можно оставить по умолчанию.
Чтобы сбор данных с Гугл Адвордс работал корректно, нужно:
- Создать отдельный аккаунт для парсинга Адвордс в Key Collector.
- Выбрать язык интерфейса в Адвордс – русский.
- Создать одну кампанию, активную или деактивированную – неважно.
Аккаунты других сервисов
Другие сервисы настраиваются и используются в тех случаях, если вы добавите их API-ключ или логин и пароль, в зависимости от сервиса.
Вкратце рассмотрим несколько сервисов и их подключение. Они находятся в разделе «Платные API».
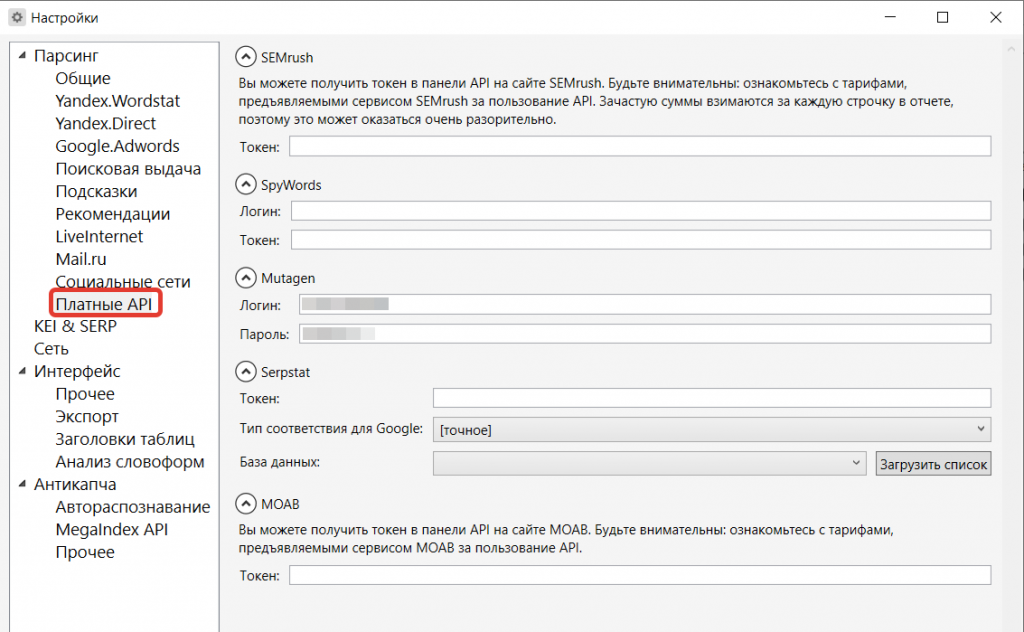
- SEMRuch. Собирает и анализирует фразы конкурентов. Для доступа нужен оплаченный аккаунт в системе и токен.
- SpyWords. Для сбора статистики из этого сервиса нужно зарегистрироваться в нет, а затем ввести логин и пароль в настройках программы Кей Коллектор.
- Mutagen. Чтобы получить данные по конкуренции и/или частотности фраз из Мутагена, нужно ввести в Кей Коллектор логин и пароль.
- Serpstat. Для сбора статистики сервиса Серпстат необходимо получить токен в кабинете сервиса и оплатить тариф.
- MOAB. Дает возможность собрать частотности из своей базы. Для получения доступа нужен логин и пароль + оплаченный аккаунт самого сервиса.
Антикапча
Для полной автоматизации парсинга нужно добавить ключ из сервисов антикапчи.
Кей Коллектор поддерживает 3 сервиса:
- anti-captcha.com;
- rucaptcha.com;
- capmonster.cloud.
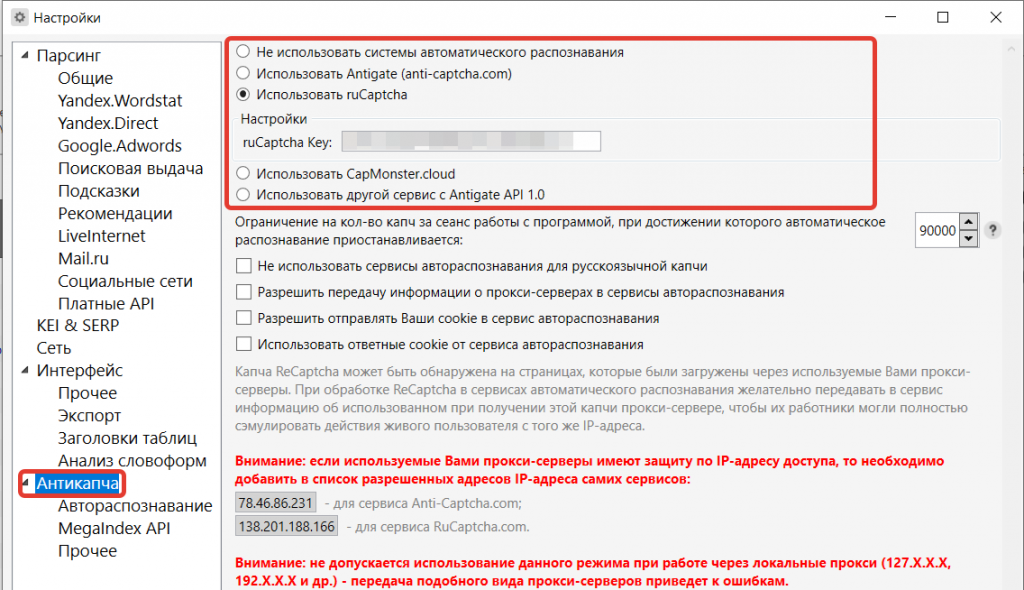
Можно установить лимит, ограничив количество распознавания капч. Для больших проектов лучше ставить максимальное значение, чтобы парсинг не прекращался.
Рассмотрим добавление антикапчи на примере Рукапчи.
Создайте аккаунт в сервисе и пополните счет.
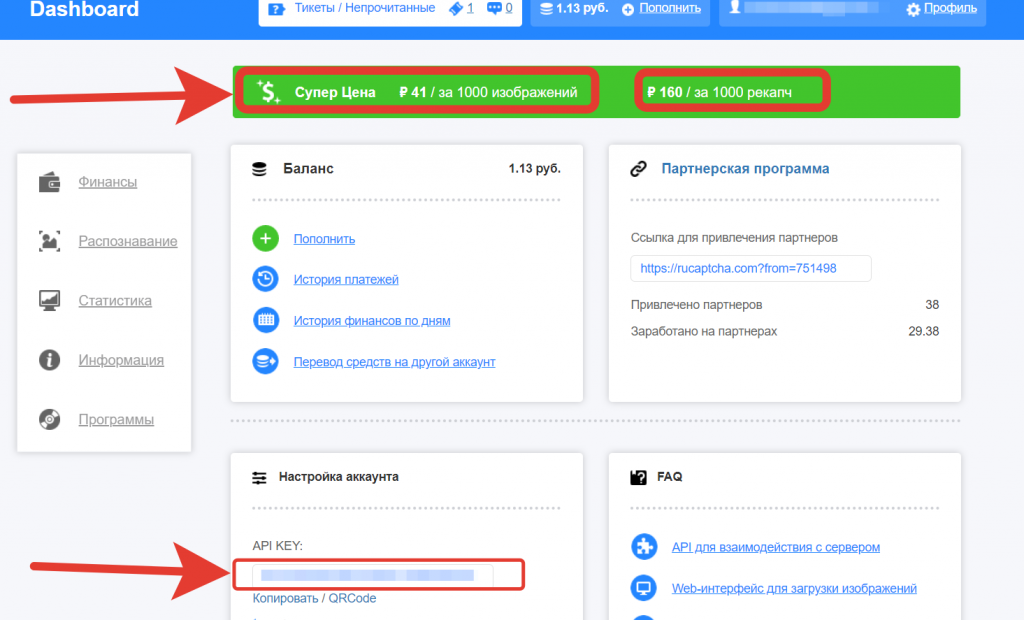
Обратите внимание на стоимость распознавания капчи и рекапчи. Последняя капча от Гугл. API-ключ нужно скопировать и добавить в Кей Коллектор.
Аналогичным способом добавляются и другие Антигейт-сервисы.
Прокси
Ускорить процесс в работе с большими ядрами поможет прокси – программа будет работать в несколько потоков.
Помните: количество потоков = количеству прокси = количеству аккаунтов.
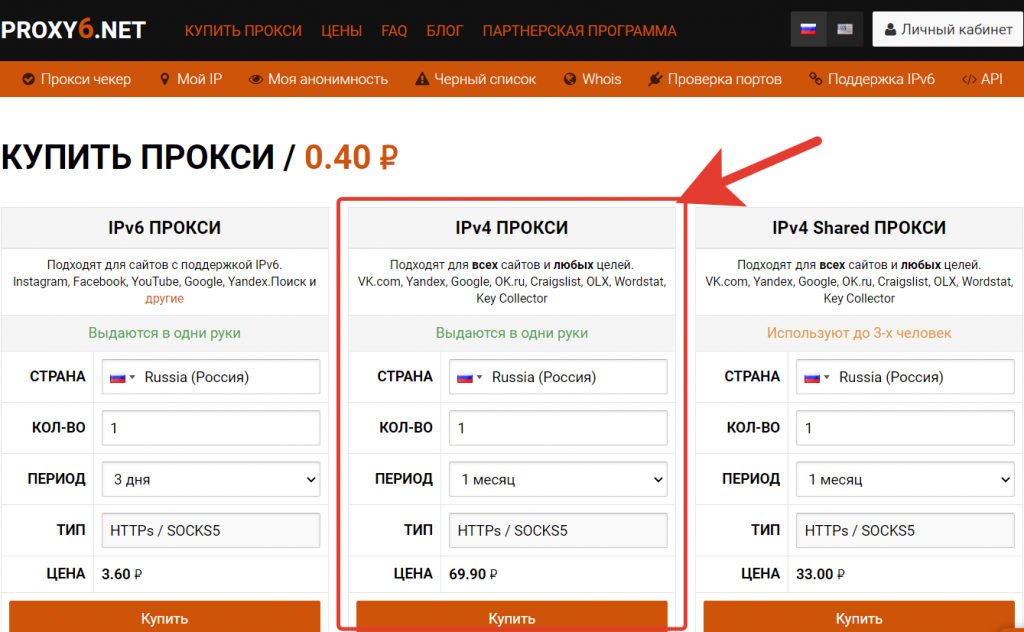
Есть множество сервисов по продаже прокси, я рекомендую тот, которым пользуюсь сам: proxy6.net Стоимость приемлемая и качество на уровне.
После создания аккаунта выберите прокси IPv4. Они подходят для Яндекса. IPv6 не поддерживаются, а Shared прокси, как правило, заспамлены, так как выдаются сразу в трое рук.
После оплаты нужного количества прокси нажмите на «Экспорт» и сформируйте список по шаблону, чтобы было удобно добавить в Кей Коллектор. Программа поддерживает формат host:port@user:pass.
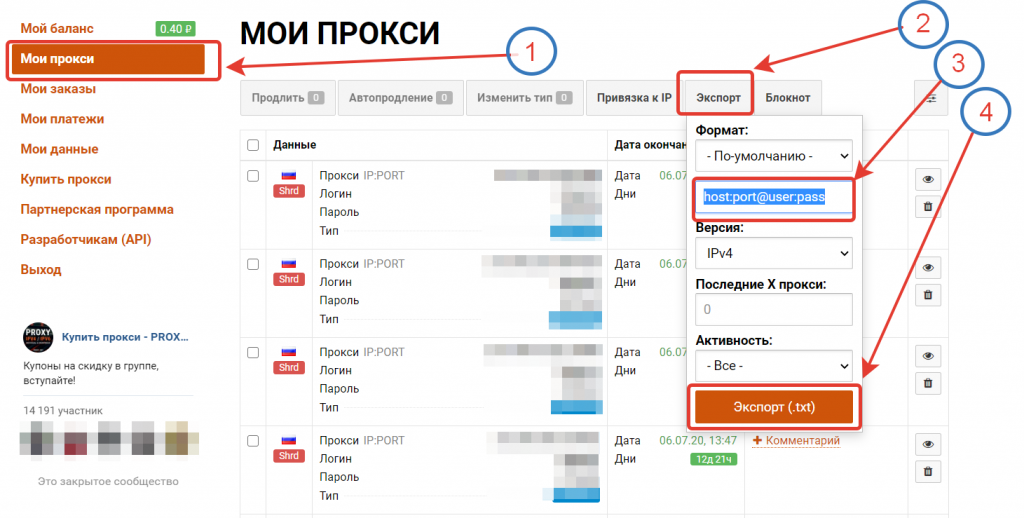
Осталось добавить и протестировать купленные прокси.
В разделе «Сеть» нажмите кнопку «Добавить из буфера».
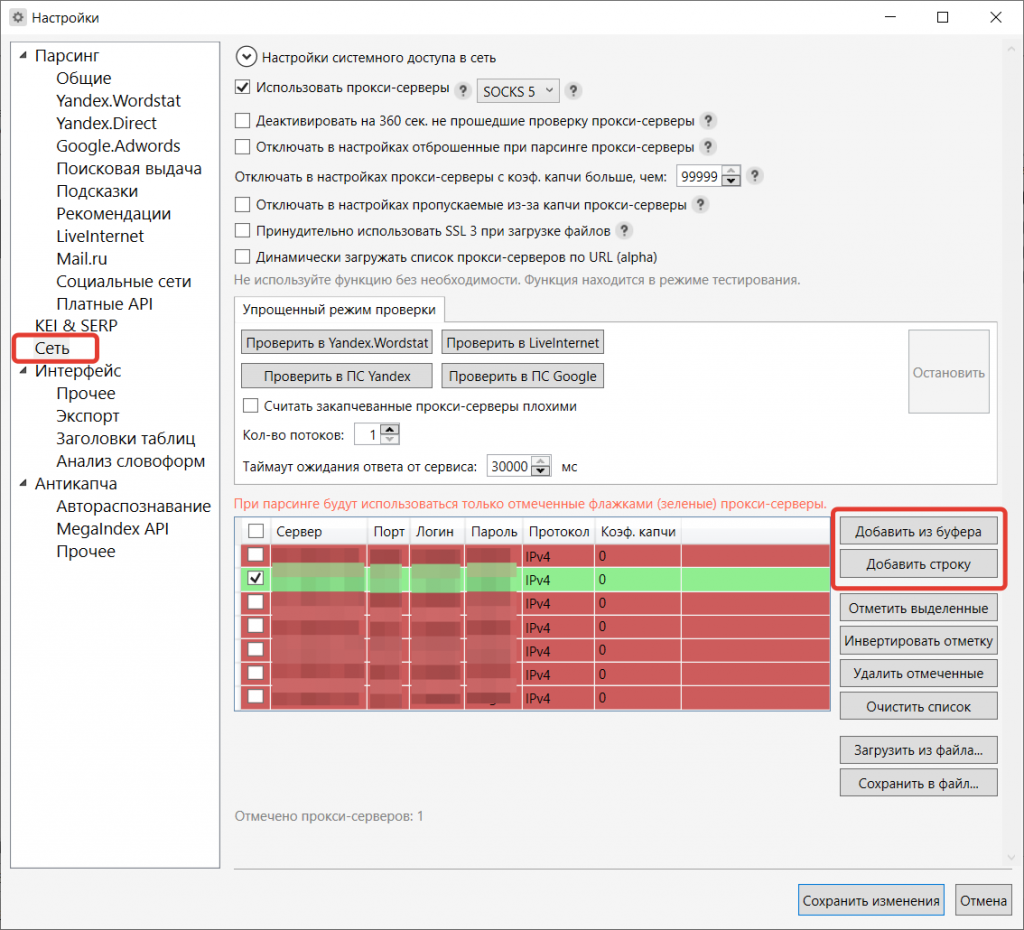
В открывшееся окно вставьте купленные прокси и нажмите «Ок».
Далее можно проверить прокси в Yandex Wordstat. Если какой-либо сервер окажется не рабочим, пишите в поддержку сервиса, в котором он был куплен, и требуйте замены.
Чтобы все работало как часы, нужно еще и зарегистрировать, а лучше купить аккаунты для каждого IP адреса. Купить аккаунты Яндекса можно в install-shop.ru.
Главное, выбирайте те, которые в доменной зоне yandex.ru и подтверждены по СМС.
Для добавления прокси, связанного с аккаунтом, нужно перейти в раздел Yandex Direct в настройках Кей Коллектор, привести прокси и аккаунт к следующему виду.
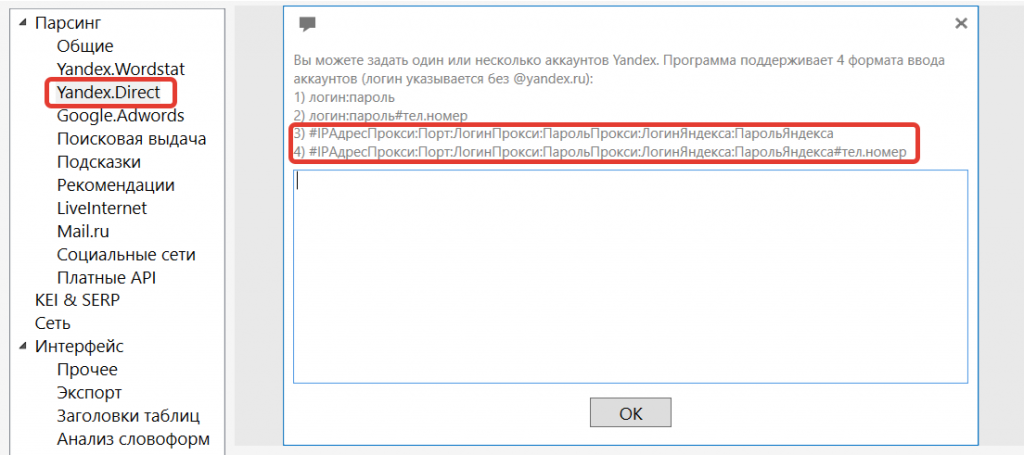
Пример корректной связки: #123.123.12.123:100:loginproxy:parolproxy:akkauntyandex:password.
Каждый прокси-адрес будет использовать свой аккаунт, что позволит парсить быстрее и с минимальной тратой антикапчи.
Парсинг Вордстата
После настройки Кей Коллектора можно начинать парсить ключевые запросы.
Первым делом определитесь с регионом. Если он не важен, ничего не меняйте. В противном случае выберите нужный регион в открывшемся окне, как это показано на скриншоте:
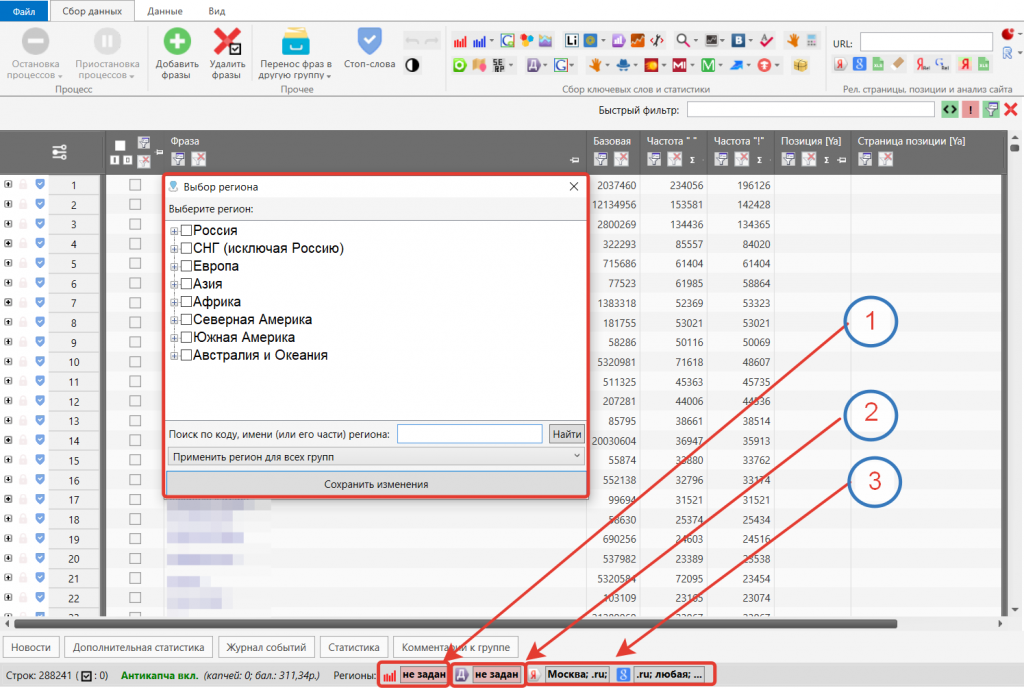
- Первый – регион, по которому будут собираться ключи и частотности Вордстат.
- Второй – получение частотностей Директ из определенного региона.
- Третий – выдача, например, подсказки, или съем выдачи для группировки по определенному региону.
Собранные маркеры нужно добавить в парсинг Вордстата. О том, как собирать маркеры для семантического ядра, читайте в нашей статье →
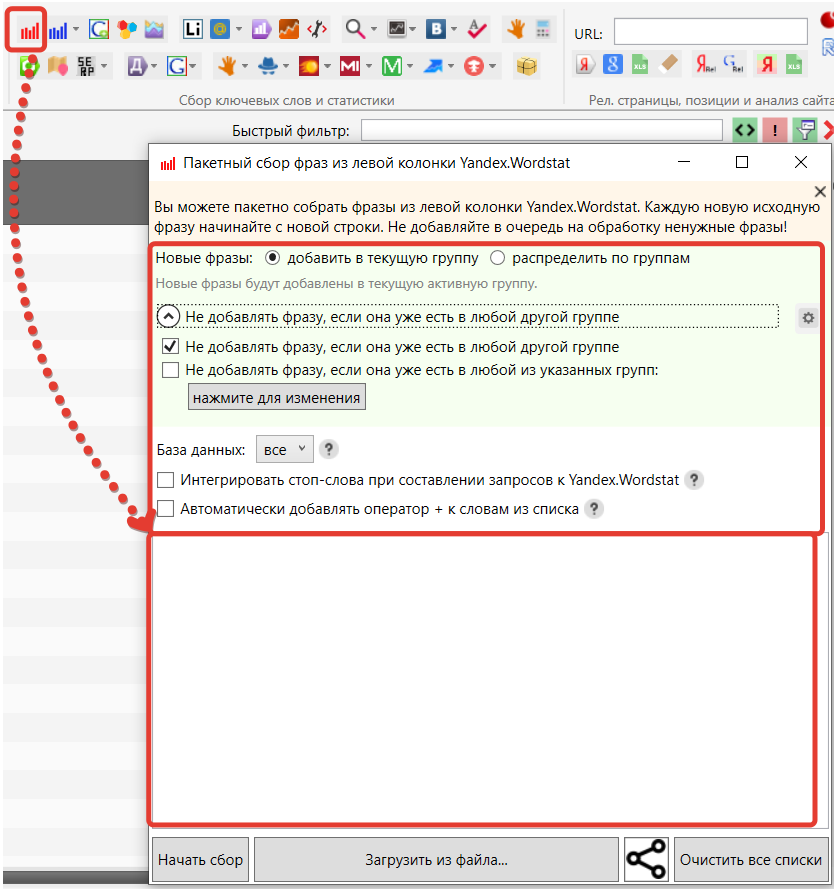
Если в Кей Коллектор уже есть несколько групп, а парсинг не первый, стоит поставить галочку напротив «Не добавлять фразу, если она уже есть в любой другой группе», или выбрать такие группы вручную.
Можно выбрать в пункте «Базы данных» платформы, с которых будут парситься ключи. Возможные варианты:
- Все.
- Десктопы.
- Мобильные.
- Только телефоны.
- Только планшеты.
Если планируется дальнейшая работа по группировке ключей в Кей Коллекторе, уместно сразу задать папки, в которые будут парситься ключевые слова. Для этого выберите «Распределить по группам».
Также ключи можно загрузить из файла. Для детальной настройки нажмите на значок шестеренки. Если глубоких настроек не требуется, достаточно добавить ключи и нажать на «Начать сбор».
Сбор частотностей
После получения данных из Вордстата или других источников нужно собрать частотности, чтобы оценить спрос. На его основе будем делать группировку и составлять ТЗ.
Для этого есть 2 основных варианта.
- Можно собирать частотности с помощью кнопки «Сбор частотности из сервиса Yandex Wordstat». Это медленный вариант, он подходит для сбора частотностей фраз состоящих из 8 слов и более. В других случаях используйте следующий вариант.
- Лучше всего собирать частотность с помощью Yandex Direct. Программа будет обрабатывать слова не по одному, а целой пачкой зараз.


При сборе частотностей Директ можно указать, какие снимать и за какой период.
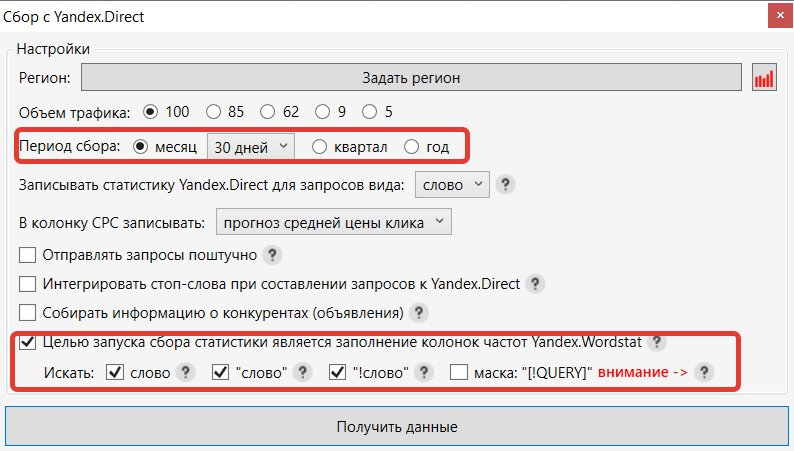
- Рекомендуется снимать частотности за последние 30 дней, если это не сезонные запросы. При съеме за другой период могут получиться не совсем адекватные цифры – видимо, Яндекс не хранит точные данные за более длительные периоды или выдает их в округленном виде.
- Съем фраз разных частотностей можно разбить на 2 или 3 этапа. Например, сначала снять базовую частотность (если добавлены запросы из других источников), отфильтровать по частотности и удалить запросы ниже определенного порога. Далее снять частотность в кавычках, снова отфильтровать запросы с неподходящей частотой и удалить их. И только потом снять самую точную частотность. Таким образом, процесс съема будет дешевле и быстрее.
Сбор подсказок
Сбор подсказок помогает получить самые распространенные продолжения фраз, в соответствии с Яндексом и Гуглом, а также другими поисковыми системами.
Для сбора добавьте маркеры в поле по аналогии с рассмотренным выше парсингом Яндекс Вордстата.
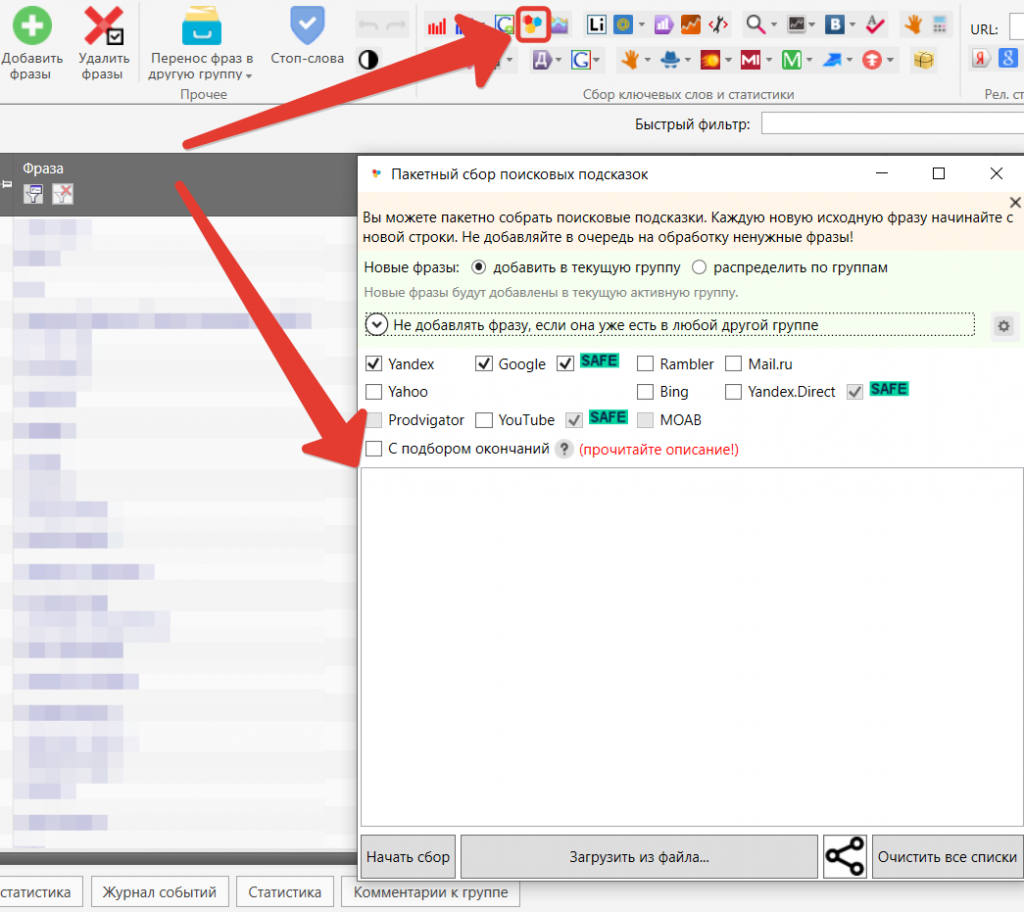
Подробнее о сборе подсказок и их настройке читайте в нашей статье →
Сбор Гугл Адвордс
Парсинг Гугл Адвордс – не самый лучший метод для расширения ядра. Ключей там мало, а в результате много мусора.
Но если спарсить Гугл Адвордс все-таки нужно, потребуется настроенный аккаунт gmail в Адвордс, как мы уже говорили ранее. И список маркеров для парсинга. Их нужно загнать в окно, которое открывается при нажатии на пиктограмму, как на скриншоте ниже.
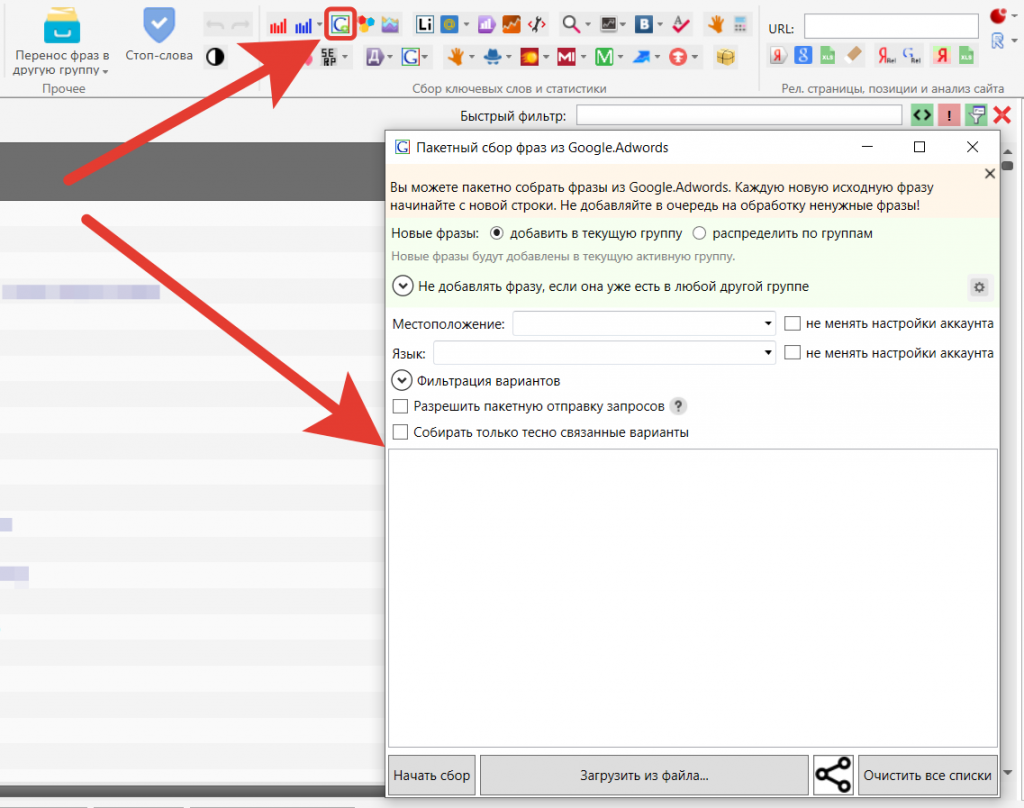
Неявные дубли
Съем данных Гугл Адвордс полезен для быстрого сравнения и удаления менее частотных неявных дублей с перестановкой слов.
Для этого нужно настроить аккаунт Гугл в программе. Для вызова функции нажмите на иконку, как это показано на скриншоте:
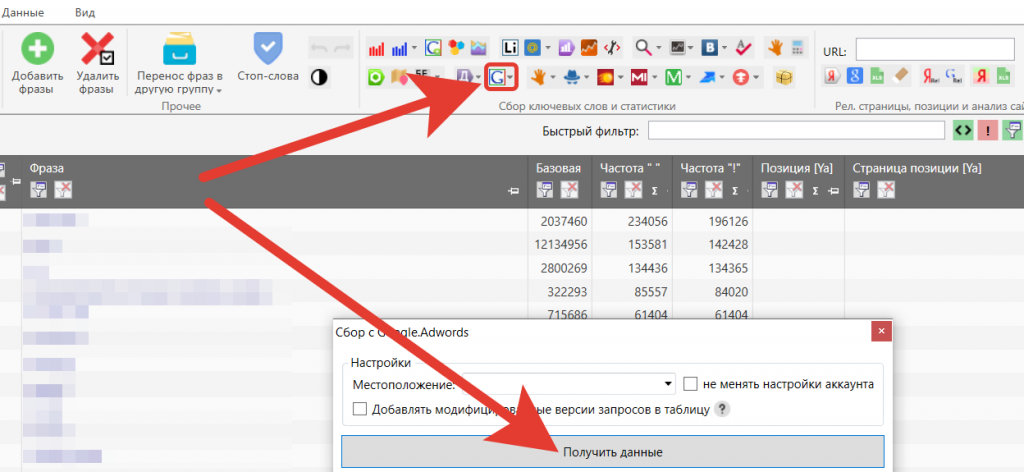
После парсинга Адвордс перейдите во вкладку «Данные» в меню «Анализ неявных дублей».
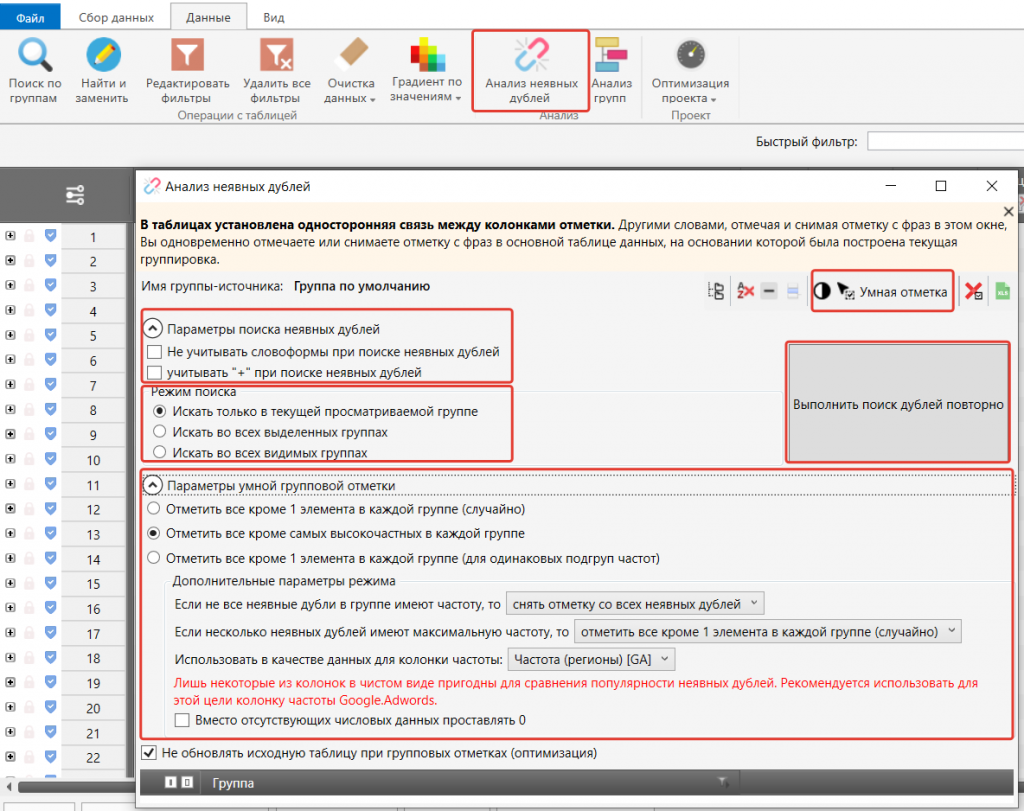
- Чтобы оставить все многообразие словоформ, снимите галочку с пункта «Не учитывать словоформы при поиске неявных дублей». Если нужна только одна морфологическая словоформа, самая частотная, то, наоборот, поставьте галочку в чекбокс.
- Выберите, где искать дубли.
- Чтобы оставить одну и исключить случайное удаление фраз со снявшейся частотой, выберите такие же параметры, как на скриншоте выше.
- Нажмите кнопку «Выполнить поиск дублей повторно».
- Отметьте дубли с наименьшей частотностью с помощью кнопки «Умная отметка».
Таким образом все неявные дубли будут отмечены в таблице и их можно удалить.
Стоп-слова
Для чистки ядра используйте стоп-слова. Нажмите на иконку в меню и добавьте список стоп-слов.
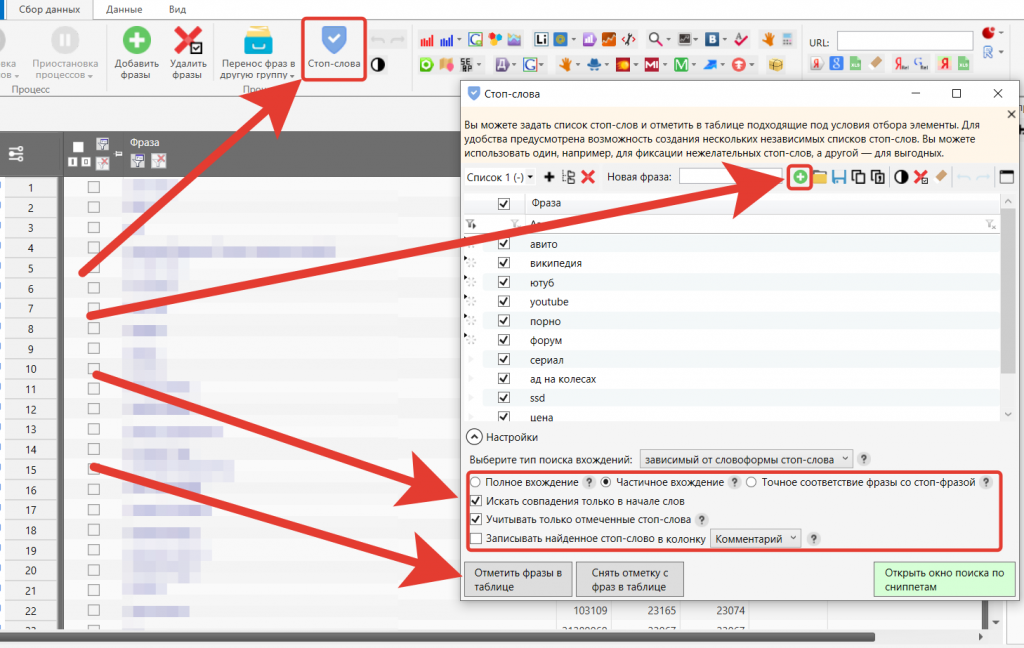
Лучше выбрать пункт «Частичное вхождение» и поставить чекбокс «Искать совпадения только в начале слов». Таким образом удастся избежать случайного удаления ключевых фраз, если пересечение с минус-словами было в середине слов и использовались короткие стоп-слова.
Еще один способ составления списка стоп-слов – это выбор из таблицы неподходящих слов.
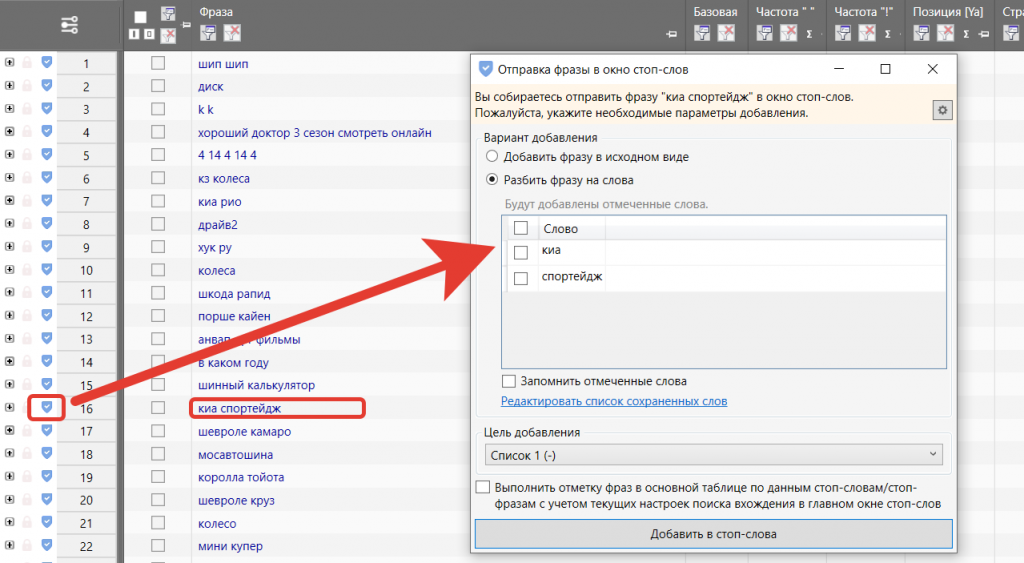
Так можно подобрать стоп-слова для текущего ядра в полуручном режиме, не используя общих стоп-слов.
Способы можно комбинировать: сначала добавить общие стоп-слова, которые подходят для большинства ядер («википедия», «авито», «ютуб» и т. п.), а потом пройтись по имеющимся фразам и поотмечать неподходящие.
Группировка
В Кей Коллекторе можно делать группировку вручную и с помощью автоматического кластеризатора.
Для ручной группировки отметьте нужные ключи и выберите / создайте новую папку для переноса.
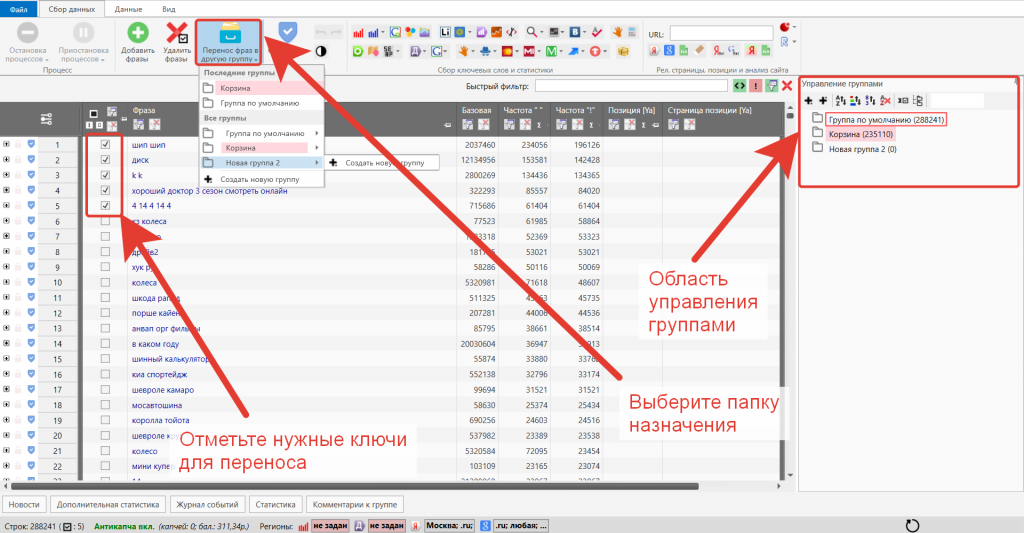
Для автоматической группировки воспользуйтесь инструментом «Анализ групп» во вкладке «Данные».
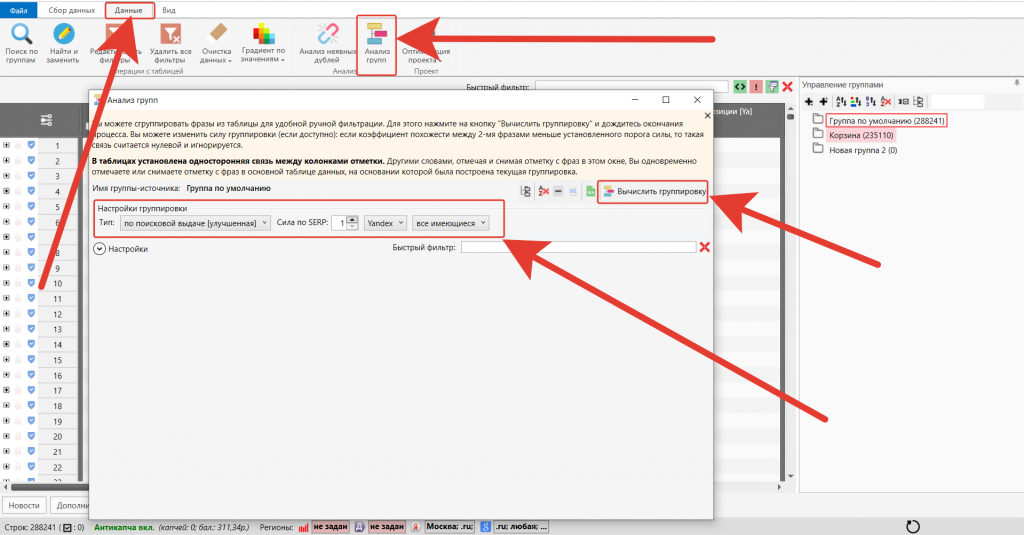
Есть несколько способов группировки и несколько уровней силы кластеризации:
- По выдаче.
- По составу фраз – группировка на основе слов в ключевой фразе.
- Комбинация этих способов.
Для кластеризации в соответствии с выдачей нужно снять ее данные. Для этого подходит инструмент Вычисления KEI.
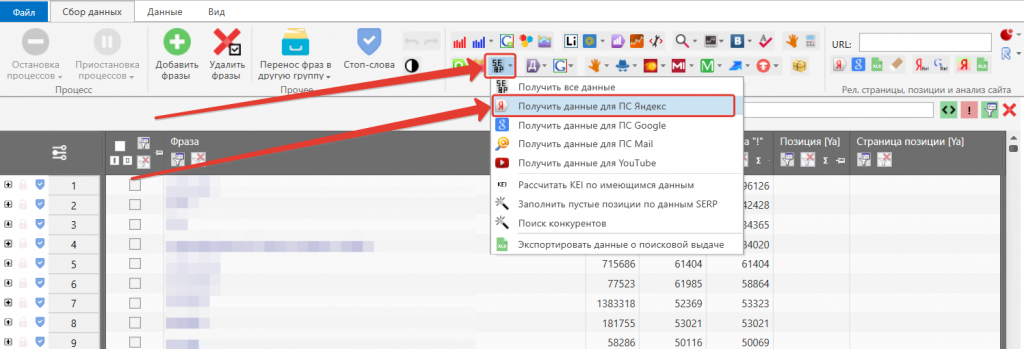
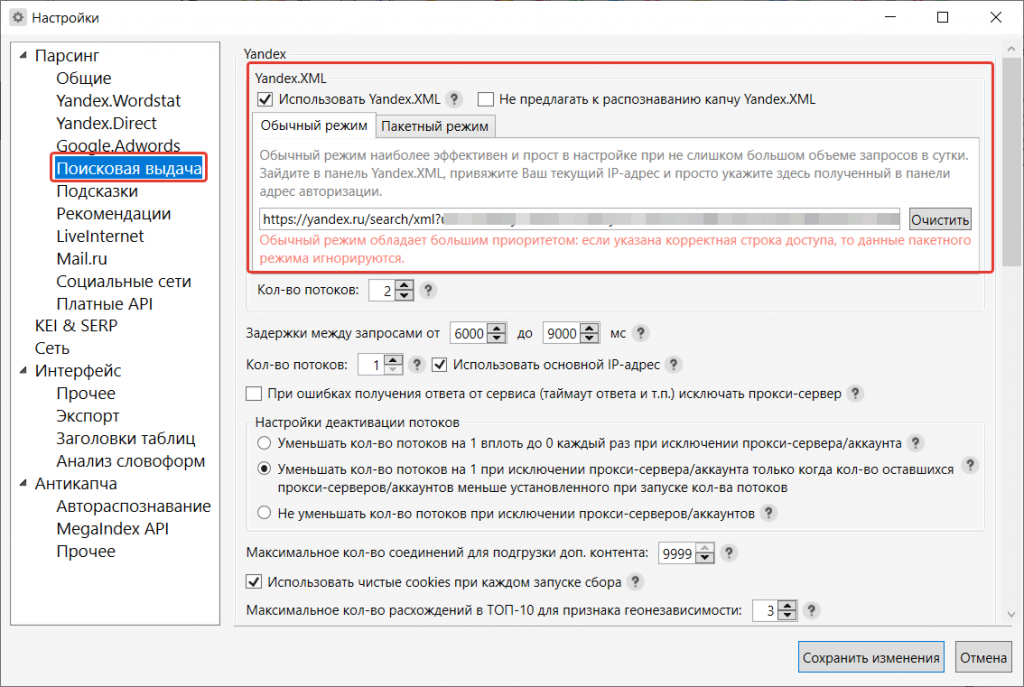
Ускорить процесс можно с помощью XML-лимитов. Также можно парсить выдачу в несколько потоков, если используются прокси.
Автоматическая группировка в Кей Коллектор не выдаст хороших групп, а наделает массу смысловых дублей, какие бы параметры кластеризации вы ни выбрали. Поэтому такой способ больше подходит для группировки мусорных фраз и дальнейшего их удаления целыми кластерами.
Экспорт данных
Для выгрузки ключевых слов укажите, какие данные нужно брать из таблицы. Это делается в настройках, в разделе «Экспорт».
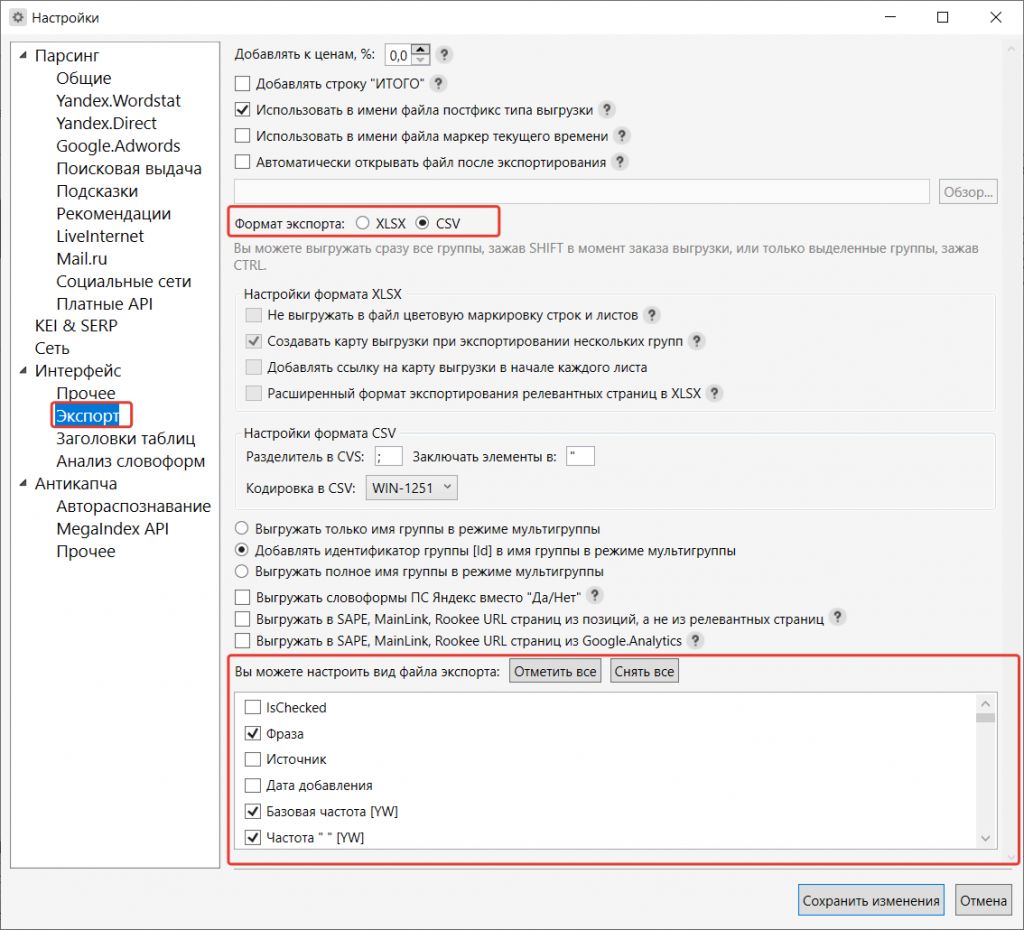
Первым делом выберите формат файла (CSV или XLSX). В самом низу отметьте, какие столбцы с данными понадобятся. Обычно выбирают следующие:
| Фраза | Базовая частота | Частота “” | Частота “!” |
Как ускорить работу программы
Если Кей Коллектор медленно обрабатывает запросы, можно попробовать оптимизировать проект.
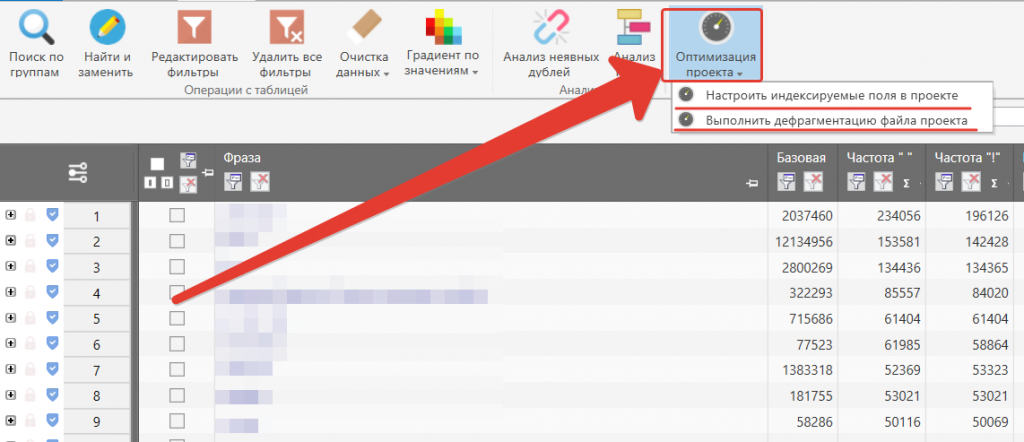
Есть 2 метода оптимизации:
- Настроить индексируемые поля в проекте. Это позволяет индексировать только ту колонку, с которой чаще всего происходит взаимодействие, например, “!частотность”.
- Выполнить дефрагментацию файла проекта. Это уменьшит размер файла на диске. Операцию можно выполнять каждый раз, когда проект начинает тормозить.
Аналоги программы
Полноценных аналогов у программы нет. Среди похожих можно выделить следующие:
- SlovoEb. Бесплатный аналог Кей Коллектора с функционалом, обрезанным до минимума.
- Магадан. Стоит 1 500 рублей. Имеет похожий функционал с Кей Коллектором. Есть бесплатная версия программы с ограниченными возможностями.
- Онлайн-парсеры. Для работы с семантическим ядром в режиме онлайн. Функционала меньше, чем Кей Коллектора, предполагают оплату ежемесячную или за проделанную работу. Подробнее о программах и сервисах для парсинга →
Заключение
Key Collector – незаменимая программа для сбора и работы с семантическим ядром, за свою цену практически не имеет аналогов. Подходит как для агентств, так и для вебмастеров.
Отличная статья по кейколлектор