Семантическое ядро (СЯ) – это список тематических поисковых фраз. Они объединяются в группы по смыслу и в дальнейшем используются для продвижения и наполнения страниц сайта, а также в контекстной рекламе.

Семантическое ядро нужно в первую очередь для эффективного продвижения сайта в поисковых системах. Каждый запрос, по которому можно найти вашу компанию или контентный проект, распределяется на страницу, которую реально продвинуть в поиске.
Семантика помогает составить полную и логичную структуру сайта, список страниц с товарами, услугами, категориями, фильтрами, а также разработать контент-план для наполнения сайта.
Рассмотрим сбор семантики для SEO (поисковой оптимизации). Основной упор сделаем на работу в русскоязычном сегменте, но посоветуем некоторые сервисы и для работы с иностранными запросами.
Виды поисковых запросов
Все поисковые запросы можно разделить на виды, в том числе по объему их показов в поиске.
Информационные
По этим запросам люди ищут информацию о вещах и явлениях, отзывы о товарах, обзоры и прочее.
Примеры информационных запросов: «первые признаки беременности», «рецепт борща», «чем отстирать пятно» и т. д.
Такие запросы в первую очередь подходят для информационных (контентных) сайтов, которые как раз и отвечают на вопросы пользователей.
Информационные запросы можно использовать и для продвижения коммерческих проектов:
- они привлекают дополнительный трафик в корпоративные блоги;
- приводят пользователя в каталоги, по ссылкам из которых он будет переходить на разделы с товарами;
- помогают расширить объем релевантного контента;
- используются для рекламы продаваемых товаров или услуг в блоге.
Как правило, частотность (количество показов) информационных запросов может быть существенно выше, чем коммерческих. Это позволяет получать большой объем трафика на сайт. Однако такой трафик будет низко конвертируемым для коммерческих проектов.
Коммерческие запросы (транзакционные)
Эти запросы пользователи используют, когда хотят купить товар или получить услугу.
Например: «купить пылесос», «гастроэнтеролог запись на прием», «доставка пиццы».
Обычно в коммерческих запросах есть слова, которые так или иначе связаны с процессом покупки:
- Розничной, личной – «цена» или «стоимость», «купить», «продажа», «каталог», «магазин» или «интернет магазин», «дешево», «недорого», «заказ»,«заказать», «розница», «доставка». А также топонимы – названия городов или областей, где пользователь собирается что-то покупать. Пример: «керамическая плитка москва».
- Оптовой – «оптом», «оптовый», «от производителя», «поставка», «поставщик», «склад». Пример такого запроса: «одежда оптом от производителя».
- Услуги – «под ключ», «на заказ», «заказать»
Витальные (навигационные, брендовые)
Витальные запросы пользователь вводит, когда его интересует сайт конкретной компании, бренда или проекта: «тинькофф», «авиасейлс», «сайт госуслуг».
Страницы этого сайта будут занимать первые строки выдачи.
Однако специально использовать навигационные запросы в продвижении не стоит, они и так окажутся в топе по соответствующим запросам.
Общие запросы
Запросы включают 1 или 2 слова, по которым невозможно определить, что именно хотел найти пользователь. К примеру, по нечеткому запросу «кот» в выдаче мы обнаружим новости, информацию о породах, интернет-магазины с зоотоварами, фото и видео с котиками.
Общие, или неточные запросы, как правило, самые высокочастотные, но использовать их для поискового продвижения бессмысленно.
Мультимедийные (фото, видео, музыка)
Как и следует из названия, такие запросы пользователи вводят, когда ищут медийный контент. Причем он может быть из самых разных областей, например, человек хочет скоротать вечер («смотреть онлайн дом 2») или готовится к ремонту («ручная дрель фото»).
В таких фразах часто есть слова «фото», «аудио», «видео», «смотреть», «слушать», «скачать».
Геозависимые (ГЗ) и геонезависимые (ГНЗ) + город
Выдача по ГЗ запросам в разных регионах будет отличаться. При этом в них не содержится указание на географическую точку. Например, если вы, будучи в Новосибирске, наберете в поисковике фразу «заказать такси» или «записаться к зубному», то увидите местные сайты. А человек в Москве по такому же запросу – столичные.
ГЗ по большей части относятся к коммерческим запросам.
Геонезависимые запросы, напротив, не привязаны к географии и покажут одну и ту же выдачу, где бы не находился пользователь. Это может быть фраза «выращивание кактусов» или «космические полеты».
Любопытно, что ГНЗ включает и запросы, в которых есть прямое указание на регион. Например, по запросу «доставка цветов рязань» пользователь увидит практически идентичную выдачу, где бы он ни находился (и в Рязани, и нет).
Запросы по частоте показов
Частота, или частотность запросов – это один из важнейших показателей для SEO-продвижения. Он выражается числовым значением и показывает, сколько раз фраза была показана в поисковой системе за месяц (реже за другой промежуток времени).
По этому параметру запросы делятся на следующие виды:
- Высокочастотные, ВЧ – самые «популярные» запросы у пользователей, их вводят чаще всего. Работать с ними непросто, так как именно по ВЧ самая большая конкуренция. Также нужно учитывать, что в точном виде пользователи используют их гораздо реже, чем с уточнениями.
- Среднечастотные, СЧ – промежуточные по частоте фразы между ВЧ и НЧ.
- Низкочастотные, НЧ – узконаправленные фразы, которые точнее и подробнее всего показывают потребность пользователя. Конкуренция по ним низкая, поэтому есть неплохие шансы попасть по НЧ в топ выдачи. Кроме того, продвижение по низкочастотным запросам занимает меньше времени, чем по СЧ и ВЧ.
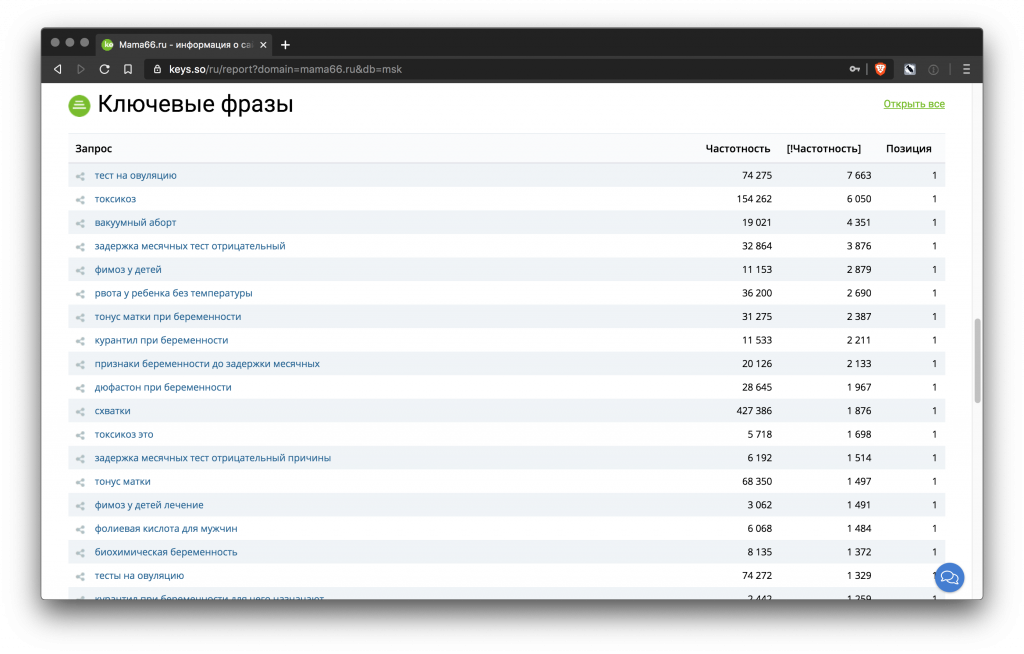
Для проверки частотности фраз при формировании семантического ядра можно использовать Яндекс Вордстат.
Пример:
| Запрос | Вид | Частота | “Частота” | “!Частота” |
|---|---|---|---|---|
| беременность | ВЧ | 9782207 | 17683 | 15612 |
| признаки беременности | СЧ | 316203 | 24925 | 24032 |
| беременность первые дни после зачатия признаки ощущения | НЧ | 88 | 9 | 9 |
Видим, что СЧ запрос в точном виде спрашивают больше, чем ВЧ.
Сбор семантического ядра
Чтобы собрать семантическое ядро, нужно придерживаться следующих правил.
Релевантность. Все запросы, отобранные для одной страницы, должны полностью соответствовать ее тематике и содержанию.
Полнота. Чтобы охватить максимальное количество релевантных запросов, нужно глубоко погрузиться в тематику проекта, изучить ее. Далеко не все нюансы темы лежат на поверхности.
Адекватная группировка. При формировании групп запросов учитывается смысловая нагрузка. Например, не берем для контентного проекта запросы с коммерческим смыслом. Также важно не создавать смысловые дубли – группы с запросами, которые выражают одно и то же разными словами.
Разграничение по типу запросов. Необходимо разделить информационные (как сделать, что такое), коммерческие и витальные.
Выбор частотности. Чтобы определить, стоит ли брать запрос и есть ли на него спрос у пользователей, смотрим на разницу между базовой (“”) и точной (“!”) частотой. Помните, что частотность может отличаться в зависимости от факторов:
- географии;
- сезонности – обзоры на кремы для загара не пользуются спросом зимой, а украшения для елки – летом, но в свой сезон эти темы популярны и частотность у соответствующих запросов высокая.
Конкуренты. Вряд ли вы будете создавать первый сайт в своей нише. Поэтому нелишним будет изучить, как работают с запросами и тематиками конкуренты из топа поисковых систем.
Работа по сбору семантического ядра делится на 3 этапа:
- Анализ конкурентов и сбор группообразующих фраз.
- Сбор поисковых запросов по всем доступным источникам и заполнение данных по частотам.
- Группировка по страницам и составление структуры сайта.
Анализ конкурентов и поиск группообразующих фраз
Будем искать фразы, которые затем вставим в Вродстат и получим расширенные запросы. Как это делать:
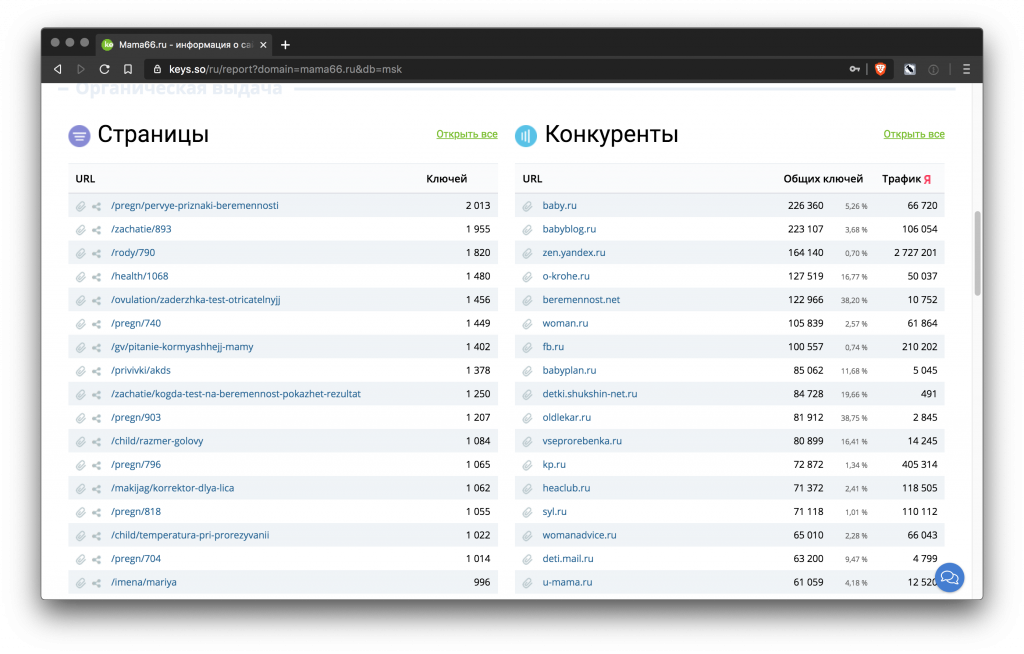
- Если в нише уже есть конкуренты, особенно с проработанными сайтами и контентом, то они нам помогут. Собираем всех, кто похож на наш сайт. Для этого есть сервис keys.so и подобные – их мы рассмотрим ниже.
- Собираем фразы из названий разделов, статей, товаров и т. д.
- Если конкурентов еще нет, то собираем свои названия услуг, категорий товаров, брендов и т. д.
Примеры группообразующих фраз: семантика, семантическое ядро, ключевая фраза, поисковая фраза, wordstat и т. д. То есть все запросы, характеризующие нашу тематику в наиболее общем виде, без хвостов. Хвост – это окончание запроса, которое уточняет его смысл.
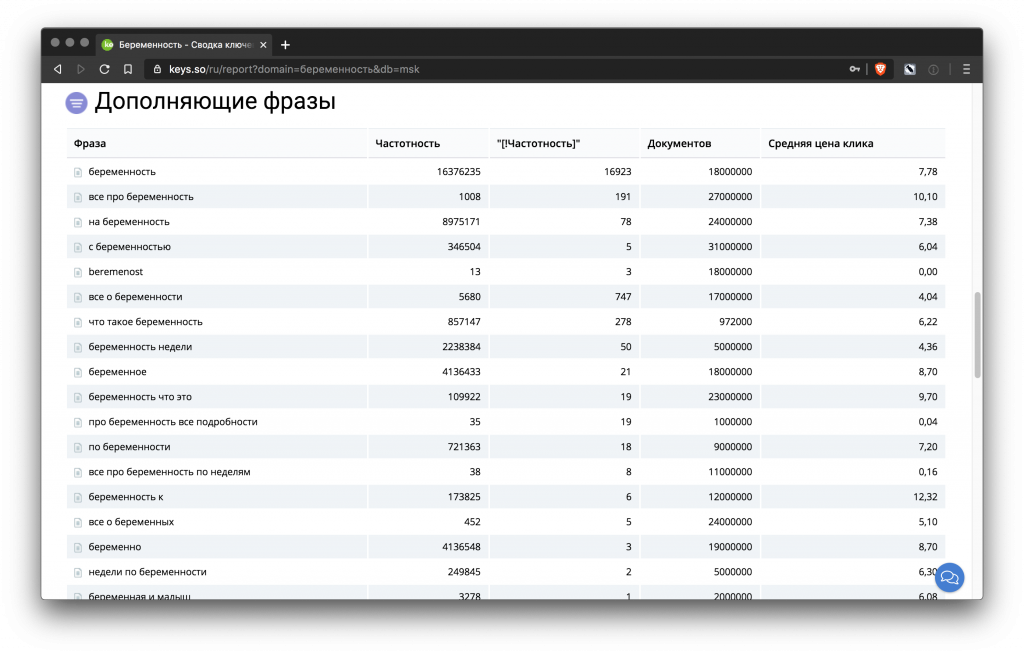
На скриншоте видно, что Вордстат по группообразующему запросу выдает еще много фраз, в которые он входит.
Чем более общее слово вы берете, тем больше лишних вариаций покажет Вордстат.
Например, по запросу «семантика» найдется и «семантика данных», и «лингвистическая семантика», которые не относятся к нашей тематике.
Все такие запросы можно будет отрезать на этапе чистки ядра или во время группировки. Избавиться от них можно и с помощью «минус-слов» на этапе парсинга Вордстата. Чтобы упростить задачу, лучше сразу брать уточненные запросы, например «семантика сайта, «сбор семантики» и т. д.
На этом этапе можно сразу создать структуру сайта.
Где собирать поисковые запросы
Чтобы максимально охватить тематику, можно комбинировать 3 варианта:
- Сбор со статистики поисковых систем – Вордстат, Гугл планировщик или Мейл.ру напрямую, либо через сторонние сервисы.
- Сбор с конкурентов.
- Выгрузка из баз данных.
Обычно хватает первых 2-х способов.
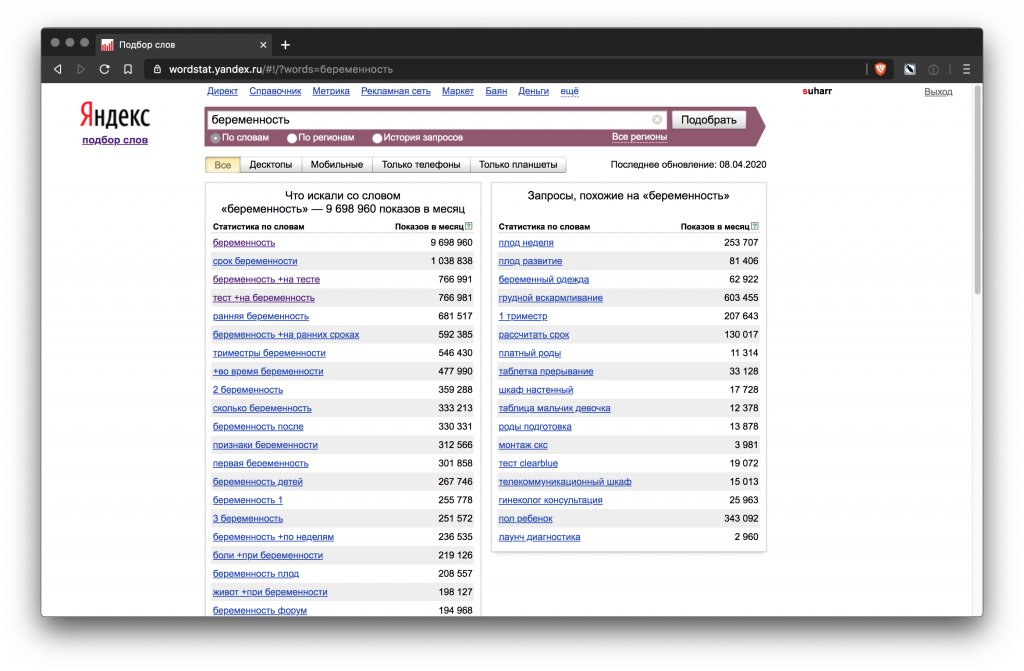
Вордстат Яндекс (wordstat.yandex.ru)
Сервис для подбора поисковых фраз и оценки их спроса в поиске Яндекса.
Вордстат дает самую точную статистику из доступных для российского сегмента. Для использования нужно иметь аккаунт в Яндексе.
Статистика разделена по типам устройств – десктопы, мобильные устройства, только телефоны и только планшеты. Можно посмотреть данные за определенный период или в динамике.
Вордстат дает данные по следующим частотам.
Базовая, или общая. Показывает общее количество запросов, содержащих указанные нами слова – во всех словоформах и порядке употребления. Для примера возьмем запрос «купить кухню». В таком виде в Вордстате он дает 917 441 показов в месяц.
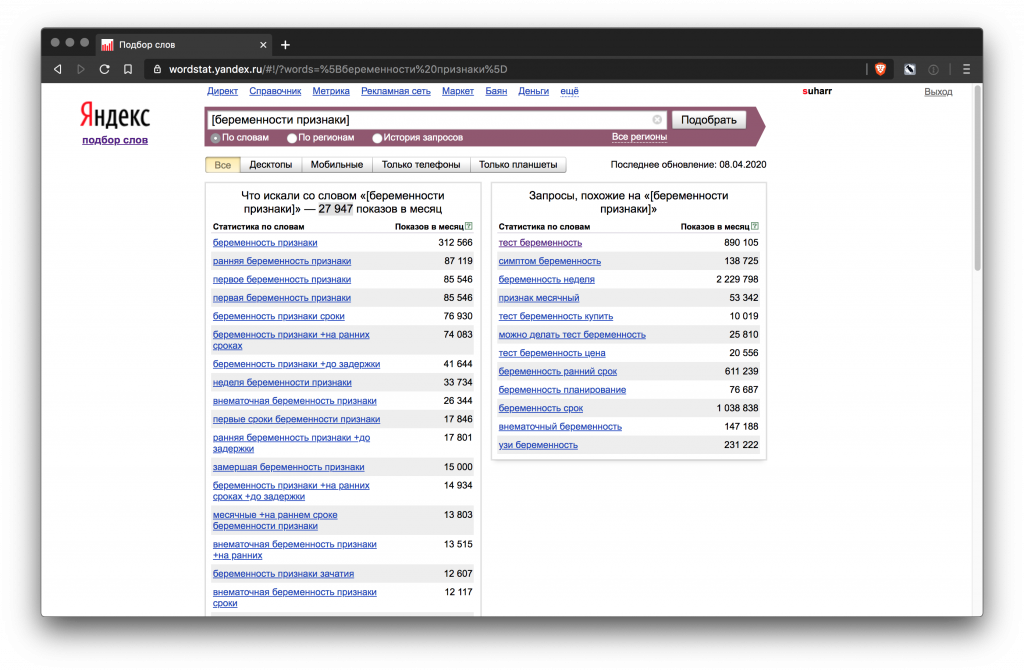
Точная. Дает более реалистичную картину. Чтобы получить ее, нужно взять слова в кавычки. Так мы узнаем, сколько показов в месяц было у нашего запроса без включения других слов, но в разных словоформах. Частота запроса “купить кухню” будет уже 22 106 показов в месяц.
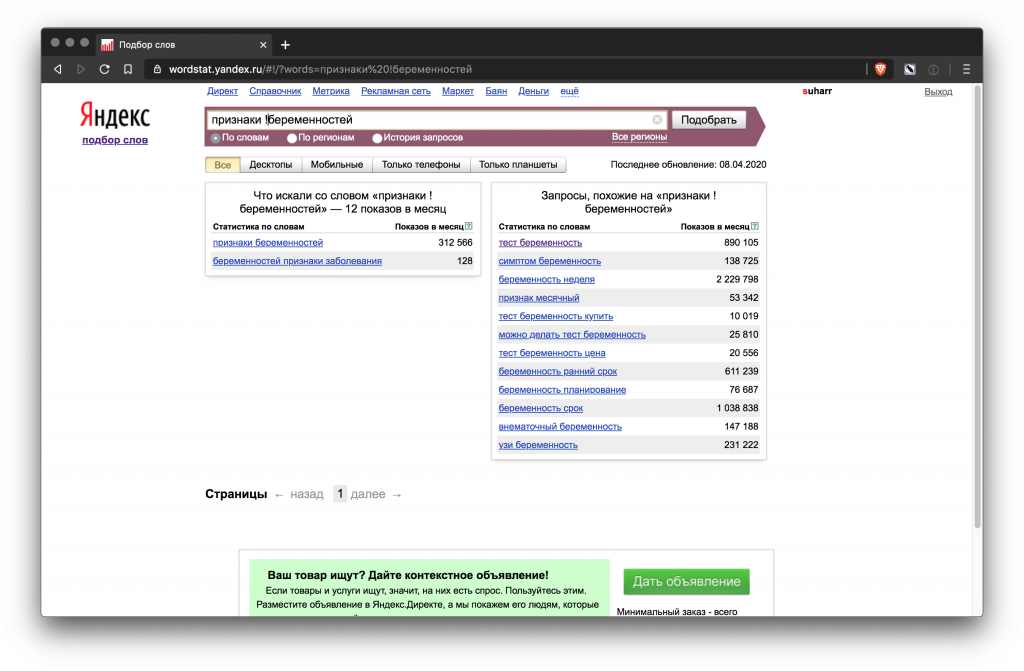
Уточненная. Учитывает показы запроса строго в указанной словоформе, без лишних слов. Для этого нужно добавить во фразу плюсом к кавычкам еще один оператор Вордстата – !
Пример: “купить !кухню” дает 15 869 показов в месяц.
Чтобы понять, какие количество трафика на самом деле дают запросы, нужно смотреть именно на точные и уточненные частотности.
C учетом порядка слов. Фиксирует порядок слов запроса с помощью оператора квадратных скобок – [ ]. Пример: [признаки беременности] и [беременности признаки] дают разные результаты.
Все эти параметры запросов “”, ! и [] можно комбинировать для поиска нужных вариантов.


Как получать данные:
- При небольших объемах можно работать напрямую с интерфейсом Вордстата, например, с помощью расширений для браузера Хром (Yandex Wordstat Helper и Yandex Wordstat Assistant и WordStater для Wordstat)
- В серьезной работе не обойтись без специализированных программ для автоматического сбора – КейКоллектор (КК) или SlovoEb. Либо использовать онлайн сервисы, которые умеют работать с Вордстатом.
- При работе с КейКоллектор можно собирать данные более эффективно через direct.yandex.ru – запросы и частоты те же, но работать с ними можно быстрее. Однако у Директа есть ограничение – нельзя проверить фразы длиной более 7 слов. Поэтому остальное проверяем через Вордстат.
Google keyword planner
https://ads.google.com/intl/ru_ru/home/tools/keyword-planner/
Для работы нужна регистрация и заполненная рекламная кампания, бесплатно.
Удобно находить смежные запросы, но для сбора большого количества ключей сервис не подходит. Статистика округленная и не годится для корректного сравнения запросов.
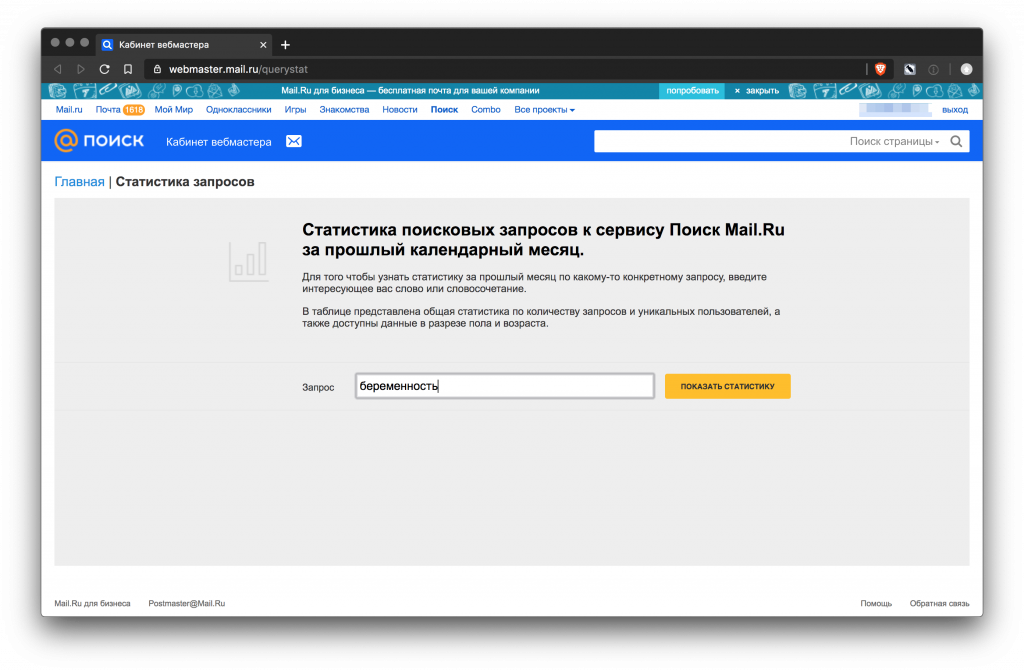
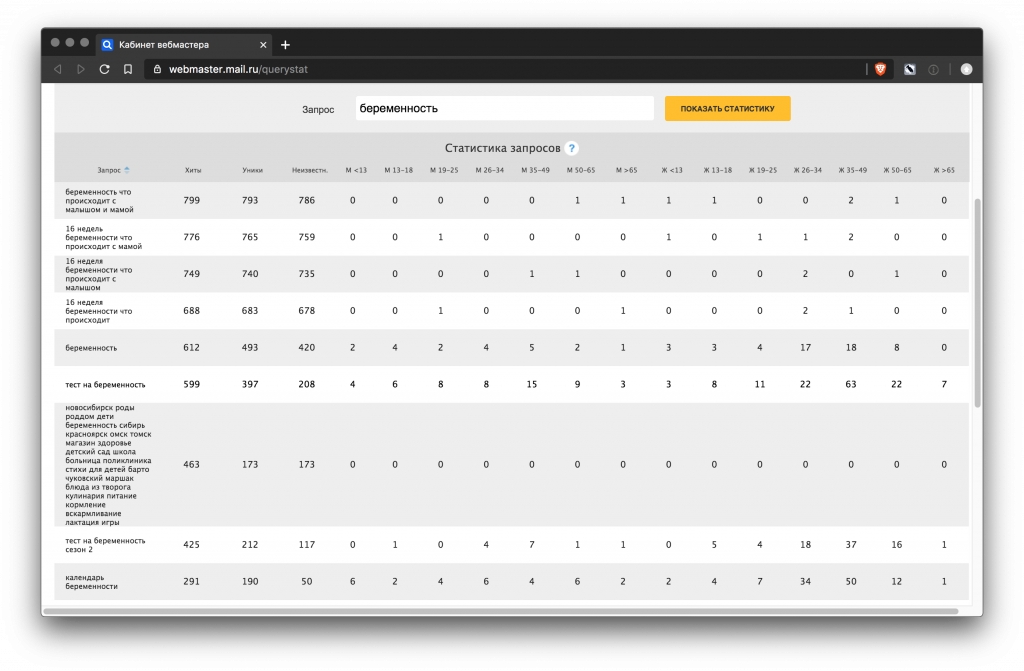
Статистика Mail.Ru
https://webmaster.mail.ru/querystat
Статистика больше подходит для анализа половозрастной структуры пользователей, чем для сбора ключей.
Сервис дает мало информации, практически нет длинных и НЧ запросов.
Подсказки поисковых систем
Лучший способ работы с поисковыми подсказками Яндекса и Гугла – через КейКоллектор.
Сейчас поисковики показывают мало данных по поисковым фразам, но все равно кое-что интересное из них можно достать.
Рекомендованные запросы из Яндекс Вебмастер
Если есть уже действующий сайт с трафиком, можно выгрузить отчеты из Вебмастера.
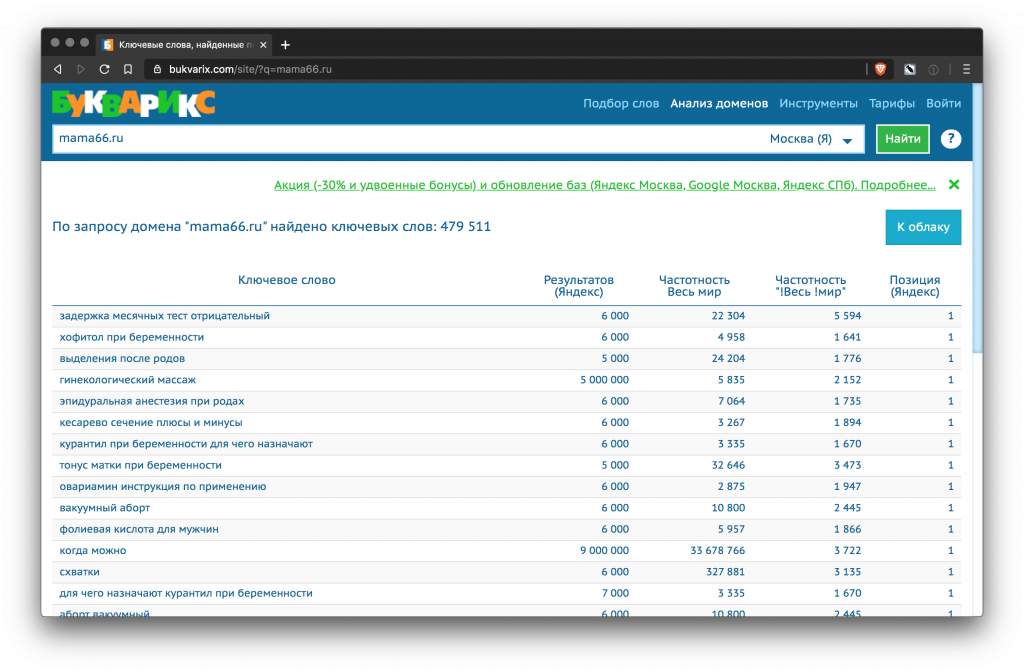
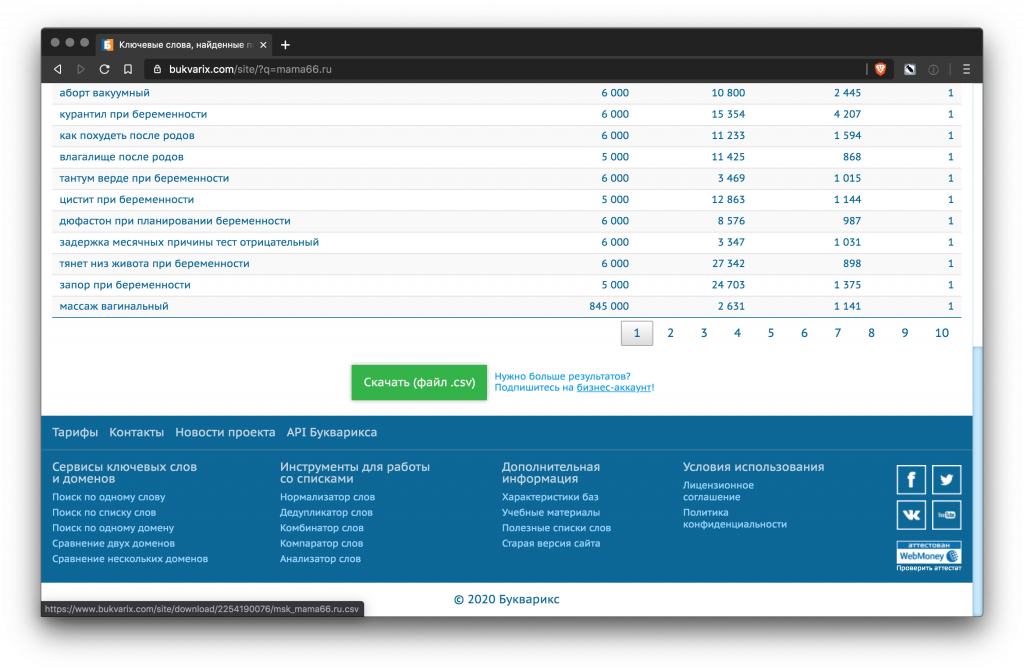
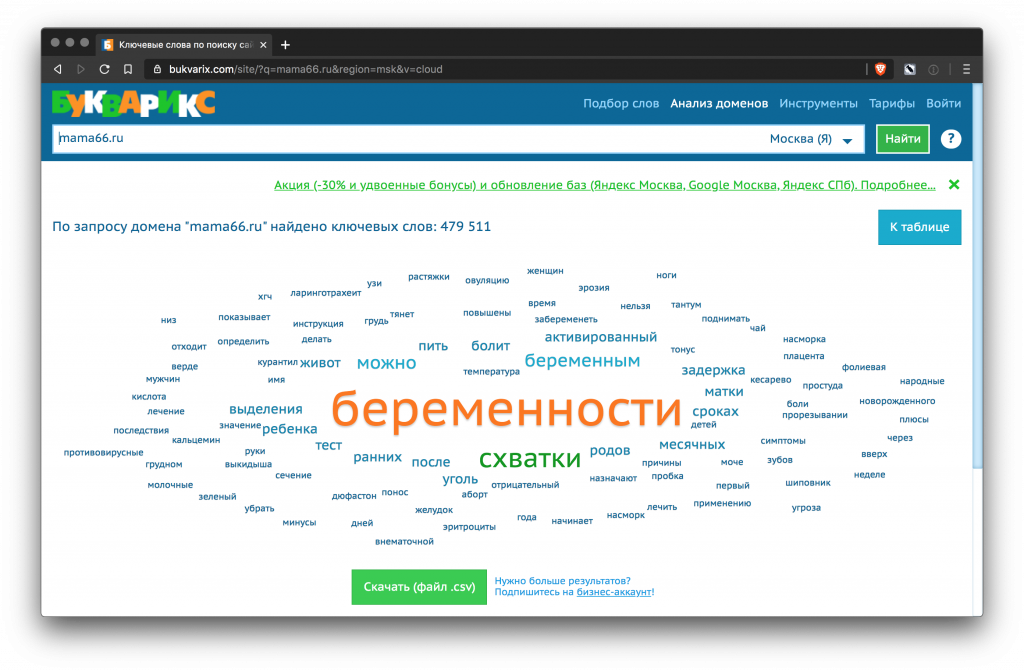
Букварикс
Сервис помогает собрать запросы, по которым ранжируются конкуренты. В бесплатном варианте до 3 тысяч строк выгрузки, в платном – до 1 млн. Стоимость 995 рублей в месяц.
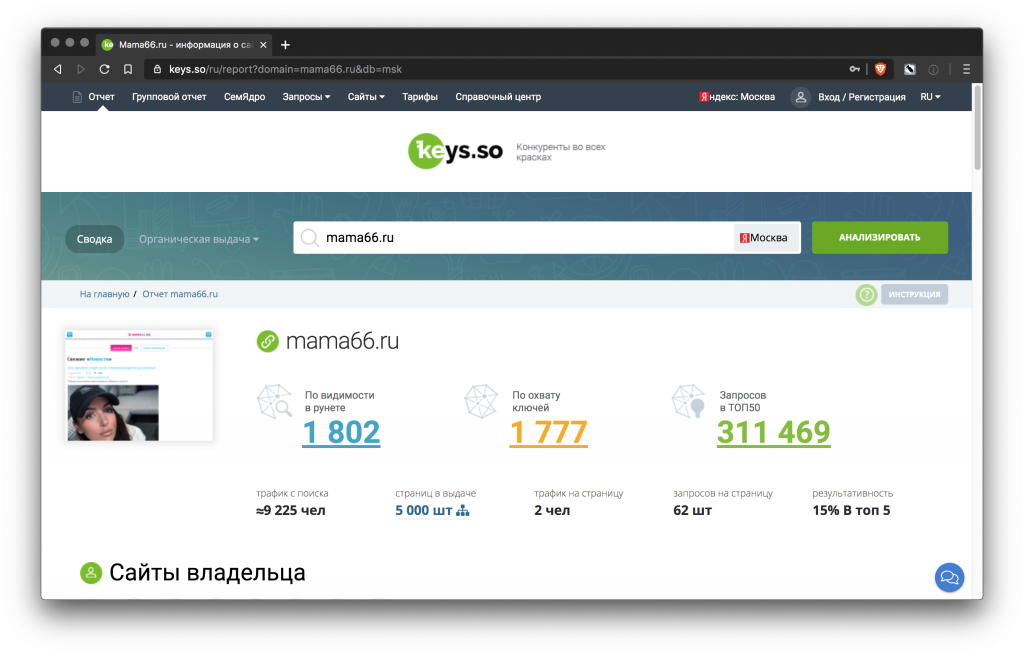
Keys.so
Более продвинутый вариант Букварикса. Помогает найти конкурентов и собрать все запросы, по которым они ранжируются.
Бесплатно можно получить только минимальный набор данных.
Самый дешевый тариф стоит 1,5 тысячи рублей в месяц и позволяет выгружать в отчетах до 20 тысяч строк, чего вполне может хватить для сайтов с узконаправленной тематикой.
-
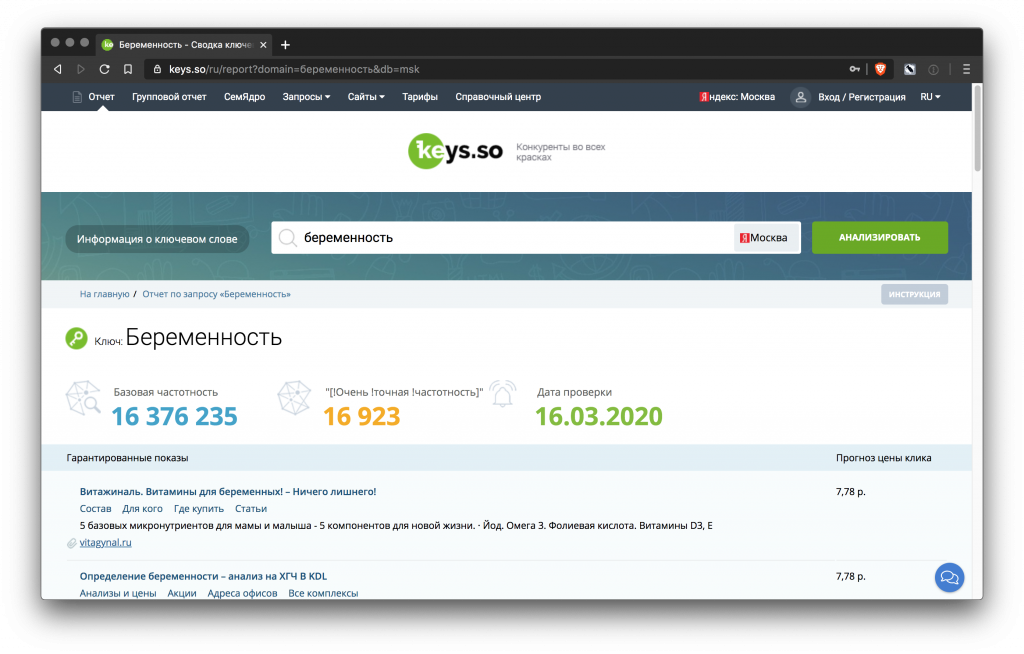
- Быстрый анализ сайта или запроса
-
- Результат анализа по запросу
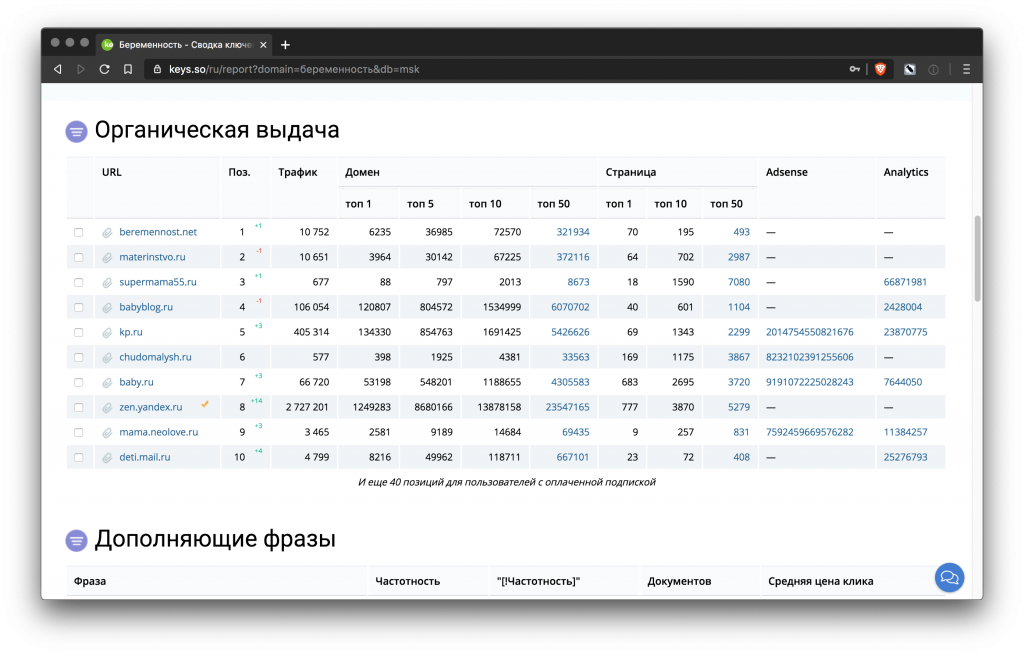
-
- Конкуренты по запросу в Яндексе
-
- Дополняющие фразы
-
- Результат анализа сайта
-
- Популярные страницы и конкуренты
-
- Основные ключевые фразы
Базы данных
Базы данных:
- MOAB, которая сейчас работает как сервис https://moab.pro/semantika;
- База Пастухова https://pastukhov.com/.
Заголовки и тайтлы конкурентов
Для парсинга заголовков и тайтлов конкурентов, а также их дальнейшего разбора можно использовать бесплатный софт xenu links.
Статистика сайта (метрика, аналитикс, лайвинтернет)
Для доработки и расширения ядра имеет смысл использовать данные по поисковым фразам из систем статистики (метрика, лайвинтернет и т. д.) + данные из рекомендуемых запросов https://webmaster.yandex.ru/sites/
Rush analytics
https://www.rush-analytics.ru/land/parser-wordstat-onlajn
Подойдет для небольших ядер и для тех, кто не хочет разбираться в КК.
Сервис платный и не особо нужен, если есть КейКоллектор. Но если нет, то Раш Аналитикс спарсит и кластеризует ключевые слова. В настройках можно задать регион сбора и стоп-слова.
Semrush
Платный сервис с обширным набором инструментов, в том числе проводит анализ и сравнение конкурентов. Однако не работает с Яндексом.
Тарифы не дешевые – от $99 в месяц.
Mutagen
Сервис для сбора Вордстата, конкуренции, автоматической кластеризации и анализа конкурентов.
При наличии КК удобно получать с этого сервиса значения конкурентности запросов, чтобы грамотно расставлять приоритеты в контент-плане проекта.
Keywordtool.io
Требует регистрации и подписки (минимальная $69 в месяц), для России не слишком актуальная база. Бесплатно можно получить список ключей, но без частотности.
Сервис иностранный, поэтому с Яндексом не работает. Зато можно подбирать запросы для Гугла, Ютуба, Инстаграма и Твиттера – Keywordtool полностью русифицированный.
Kparser.com
Мультиязычный сервис по сбору семантики. Платный, минимальный тариф $26 в месяц, но в нем всего 2 тысячи строк для экспорта, что очень мало.
Безлимитный экспорт начинается от $30 в месяц за подписку.
Justmagic
Этот платный сервис мы протестировали в демо-режиме. Интерфейс оказался не слишком понятным, как и внутренняя система оплаты. Но полный функционал вполне может быть стоящим, так как его создатели – крутые сеошники.


Ppc-help.ru
Требует регистрации, позиционируется как сервис для директологов, но некоторые инструменты могут быть полезны и для продвижения сайтов.
В данный момент похоже, что создатели его забросили. Будем надеяться, что сайт еще поднимется.

Spywords.ru
Проводит анализ конкурентов, их запросов, рекламных кампаний и т. д.
Word-keeper.ru
Скоростной парсер Вордстат. Платно, маленькие лимиты: тариф ВИП включает всего 50 тысяч запросов.
Сервисы для работы с англоязычными запросами:
- https://keywordtool.io/
- https://www.similarweb.com/
- https://serpstat.com/
- https://majestic.com/
- https://ahrefs.com/keywords-explorer
- https://neilpatel.com/ubersuggest/
- https://ru.semrush.com/
- https://answerthepublic.com/
- https://kparser.com/
Обычно для работы хватает 3–5 источников из списка. Использование всех сервисов сразу не даст значительного роста найденных запросов, поэтому выберите те, что для вас удобны, подходят по цене – и вперед.
Сбор и обработка данных
Чтобы собрать найденные запросы в один список и начать с ними работать, нужен удобный инструмент. На рынке немного программ для этой задачи, рассмотрим эффективные:
- КейКоллектор – самый мощный инструмент по работе с данными поисковых фраз на рынке, программа десктопная для Windows. Платная, но стоит всего 1800 рублей и заплатить их нужно один раз. Можно загрузить в КейКоллектор все данные из Кейсо, Букварикса и баз данных + спарсить Вордстат и поисковые подсказки.
- СловоЁб – младший брат КейКоллектора. Бесплатный, но с урезанным функционалом.
- КейАссорт http://keyassort.ru/ – программа для сбора, структуризации и кластеризации семантического ядра.
- Обычные таблицы Эксель – ручное заполнение из доступных источников.
- Надстройка для Экселя https://semtools.guru/ru/ Добавляют дополнительную панель с инструментами и формулами для работы с семантикой. Можно купить за 900 рублей.
Группировка
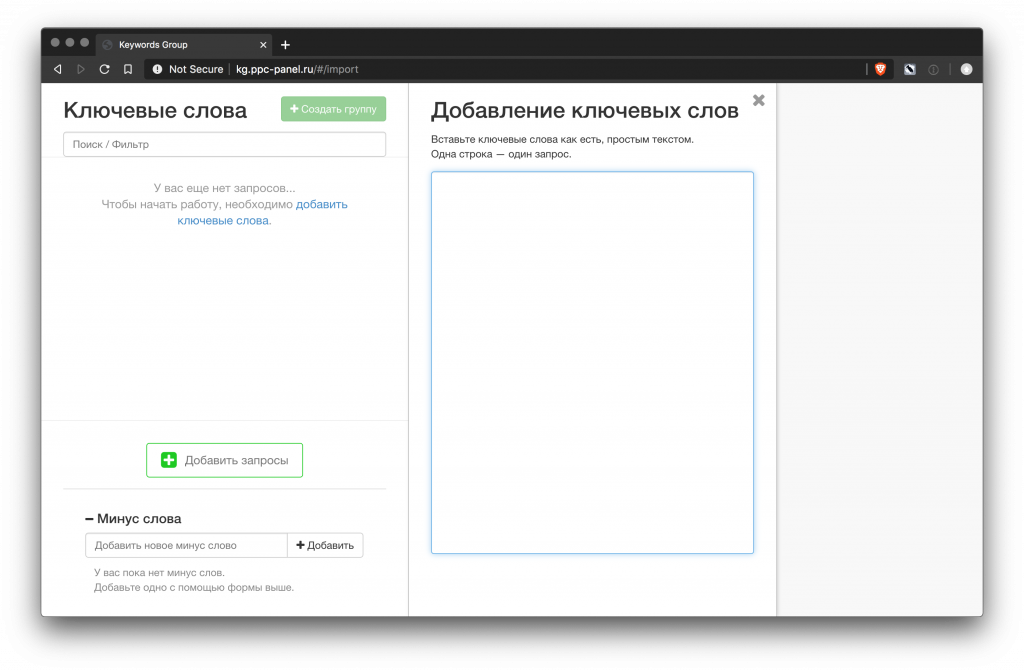
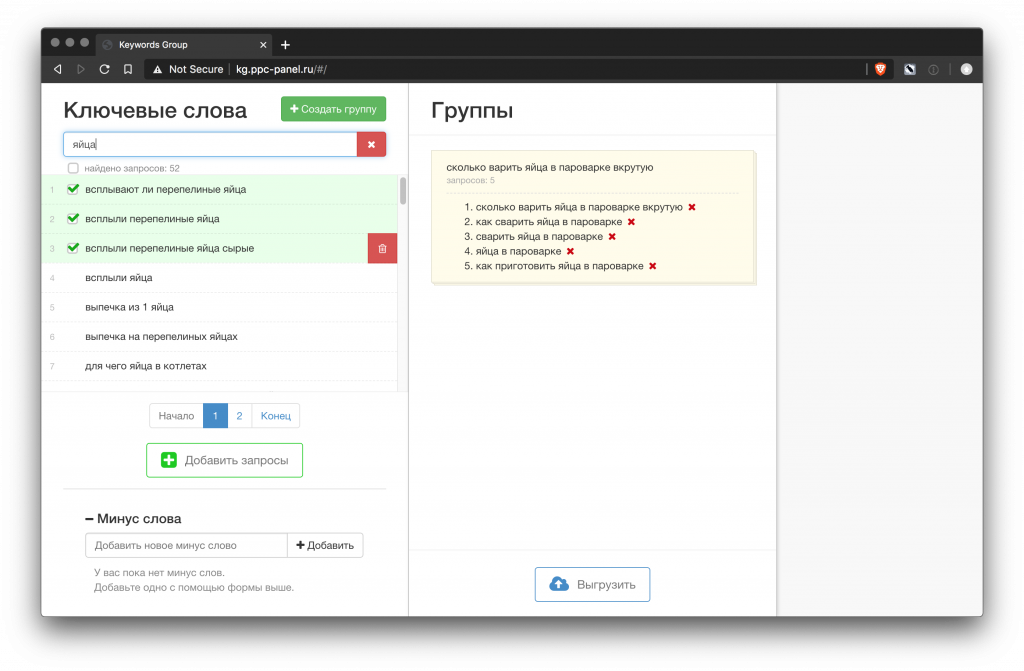
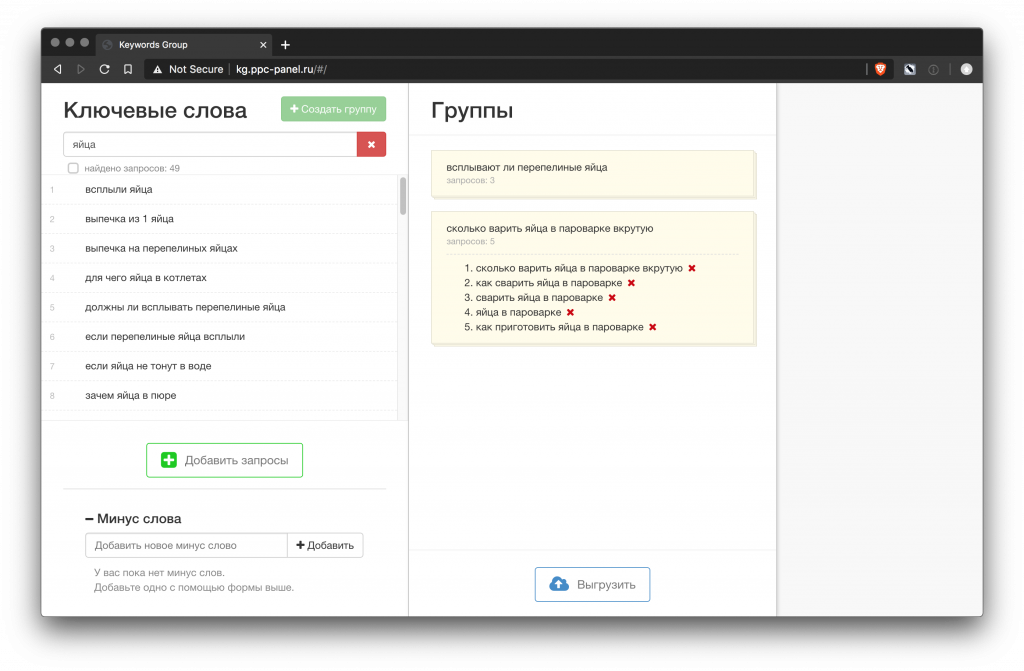
Группировка ключевых слов, или кластеризация – это их объединение запросов в группы по смыслу.
Памятка:
При группировке всегда держим в голове 2 условия:
- сможет ли этот запрос ранжироваться на этой странице;
- получит ли пользователь ответ по этому запросу на этой странице.
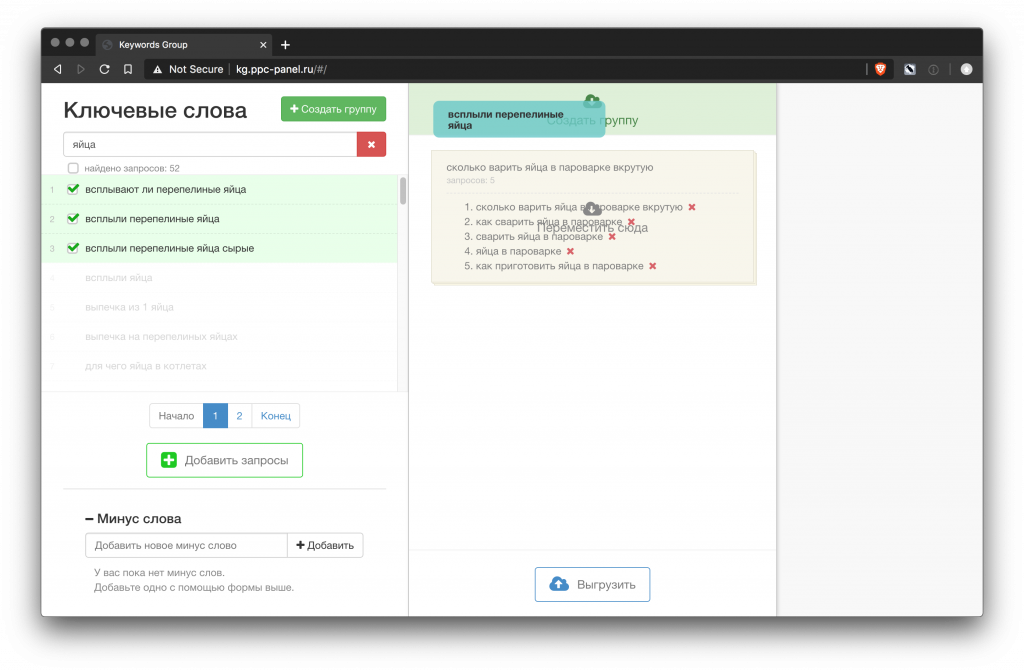
Группировка бывает автоматической и ручной. Автоматическая делится на несколько видов: по фразе, по топу (с разной степенью похожести) и на нейросетях.
То что получается на выходе из автоматической группировки, редко можно сразу взять и применить. Как правило, там много ошибок со смысловыми дублями.
Доработать автоматическое ядро бывает сложнее, чем с нуля сгруппировать руками. Зато оно отлично подходит для примерной оценки количества групп.
Ручная плохо подходит для больших ядер, так как неудобно работать с деревом групп. Автоматическая группировка, без ручной доработки, подходит, если нужно быстро оценить проект.
Есть много вариантов группировщиков как автоматических, так и ручных, например:
- КейКоллектор http://www.key-collector.ru/
- таблицы Эксель (бесплатно, скорее всего, уже есть на вашем компьютере).
- https://workflow.team/ (платно / бесплатно)
- http://kg.ppc-panel.ru/#/import (под вопросом, так как перестал работать)
- http://keyassort.ru/ (платно, десктопная программа)
- https://www.keys.so/ru/clustering (платно / подписка)
- https://topvisor.com/ (платно / бесплатно)
- https://semparser.ru/ (платно)
- https://just-magic.org/ (платно / подписка, рассчитан на специалистов
- https://mutagen.ru/?p=clasterization≈
- https://serpstat.com/ru/ (платно, от 69$ подписка в месяц, разработан https://netpeak.net/, но с 2015 года независим)
- https://arsenkin.ru/tools/clustering/ (платно / бесплатно)
Выбор сервиса – дело вкуса и потребностей. Кто-то предпочитает кластеризовать только автоматически и не тратить время, кто-то же, наоборот, как мы – группирует только руками. Многие сервисы позволяют комбинировать эти методы, поэтому выбирайте по удобству и цене.
Как работаем мы
Чтобы лучше понять процесс работы с семантикой, посмотрите, как действуем мы:
- Ищем конкурентов по выдаче, а потом через Кейсо.
- Собираем группообразующие фразы и структуру.
- В КК собираем расширения группообразующих запросов через Вордстат, т. е. собираем дополнительные запросы на основе имеющихся фраз. Если много запросов и есть риск пропустить какие-то кластеры, то по второму разу парсим Вордстат.
- Потом с помощью Кейсо и Букварикса собираем запросы с конкурентов.
- Все это загружаем в КК, с помощью прокси и аккаунтов Яндекса собираем статистику с Вордстата и расширения запросов. Рекомендуем покупать прокси один ip в одни руки. Бесплатные заспамлены и толка от них нет. Аккаунты Яндекса тоже есть смысл покупать сразу по 10–20 штук, чтобы меньше было расходов на капчи.
- Если необходимо, дополнительно собираем подсказки поисковых систем в КК.
- Чистим от явного мусора и загружаем в workflow.team.
- Иногда делаем автоматическую группировку, чтобы оценить будущее ядро.
- Далее используем только ручную группировку при анализе выдачи и погружении в тематику, чтобы по максимуму исключить смысловые дубли.
- Пишем контент и отслеживаем результаты так же в workflow.team, в модулях «Контент» и «Задачи».
- На этапе составления ТЗ на текст подбираем LSI ключи. Если делать это раньше, они могут пересекаться между группами. Но мы не можем этого допустить, потому что в наших ядрах все запросы уникальны, и не должны дублироваться в разных группах.
Нередко в сырых поисковых фразах у нас несколько сотен тысяч запросов. В самом большом ядре – более миллиона.
Сервисы типа Кейсо и Ахрефс можно использовать без подписки, с помощью кворка, особенно, если они не нужны постоянно.
Сервис распознавания капчи от rucaptcha или anti-gate по ключу в КейКоллекторе.
Надеемся, что наш опыт окажется полезным. Сбор семантического ядра – долгая и кропотливая работа. Недостаточно собрать запросы, важно оценить их конкурентоспособность и потенциал, правильно сгруппировать и на их основе составить ТЗ для копирайтера.
Если у вас есть и другие дела, которые требуют сил и времени, будем рады помочь создать для вас семантику ручной работы для завоевания топов Яндекса и Гугла.
Чтобы узнать подробности и обсудить проект – звоните, пишите нам на mail@semkeys.ru или оставляйте заявку.
Отправляя сообщение, Вы разрешаете сбор и обработку персональных данных. Политика конфиденциальности.